Enhancing Prioritization with Networks
Last month Michael Dubakov suggested using networks to prioritize features. Now let’s go further and try to turn the idea into a practical framework.
This article is meant as a standalone so reading Michael’s post is a suggestion, not a prerequisite.
What are the prioritization techniques missing?
As a diligent product manager, you’ve done customer discovery and collected feedback. You notice recurring Use Cases and even some clusters which represent Personas or Niches:
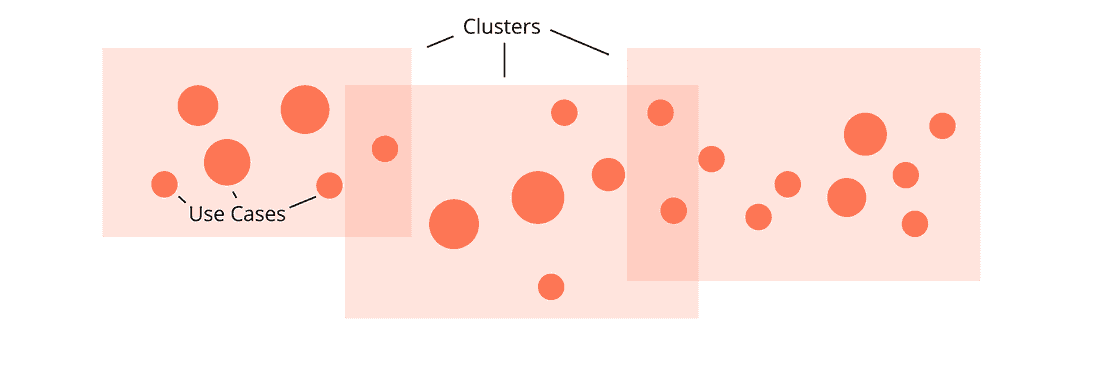
Your team blends empathy with product vision and invents Features to address the Use Cases:
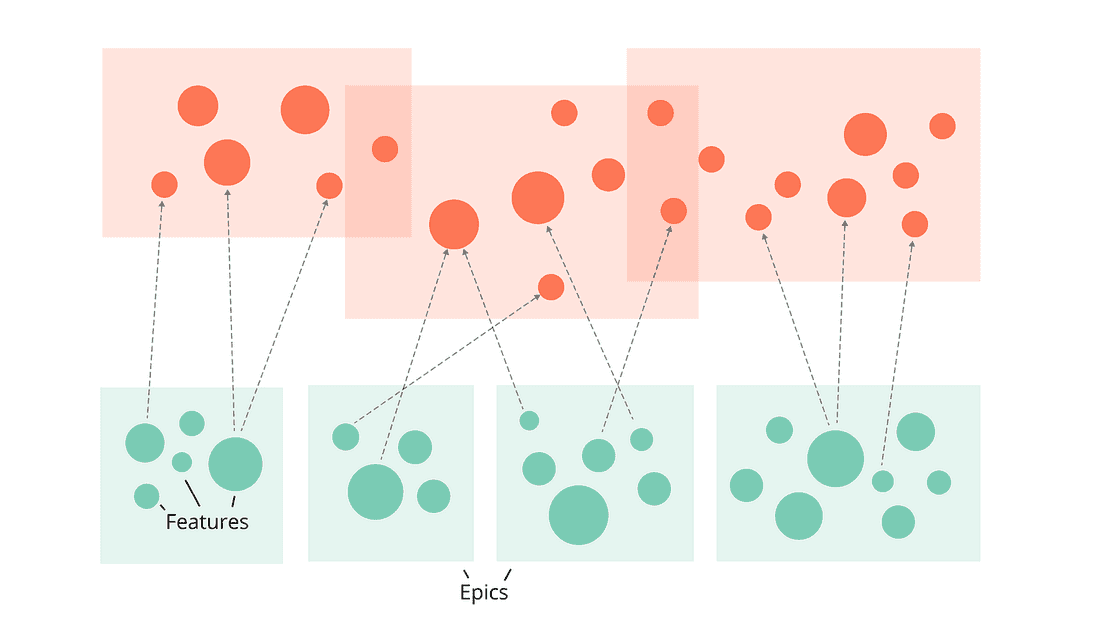
Now it’s time to decide which Features you should build next. You pick a prioritization formula like Value/Effort or RICE so your teammates can follow your thoughts and rationally debate the score.
Here is what these formulas capture:
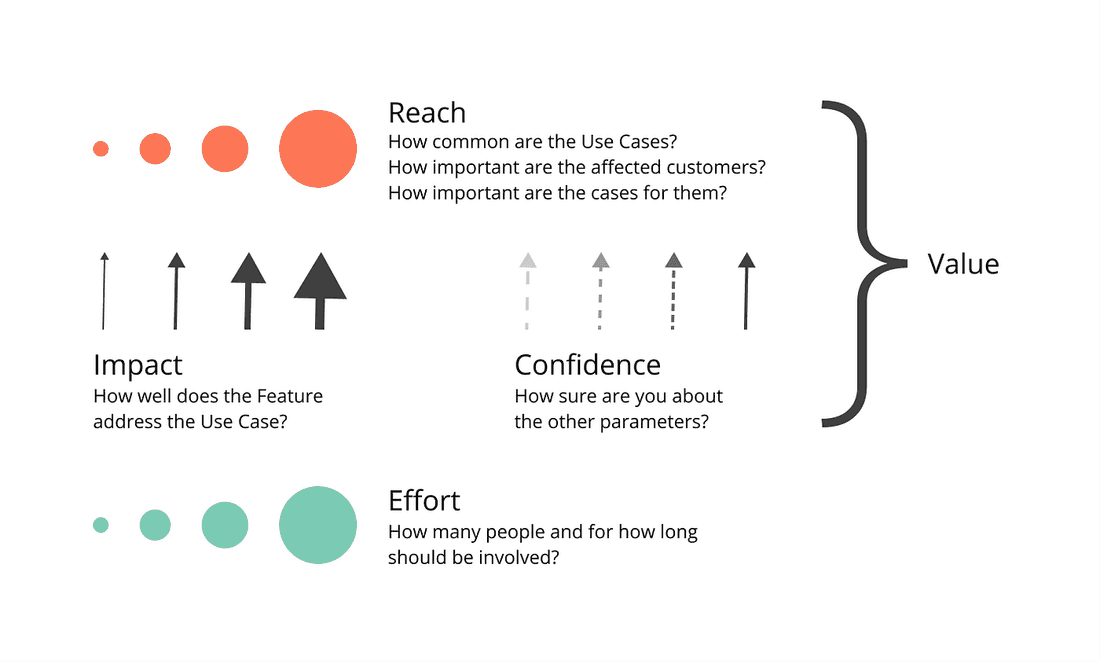
So which of the two Features below should you build next?
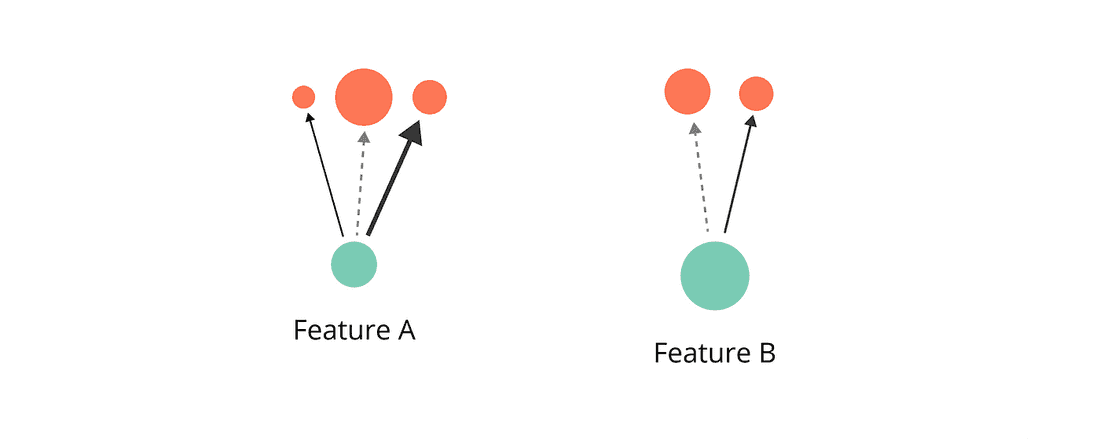
Feature A has more value and takes less effort so it’s a no-brainer, case closed? Not so fast. The formula fails to capture two important factors.
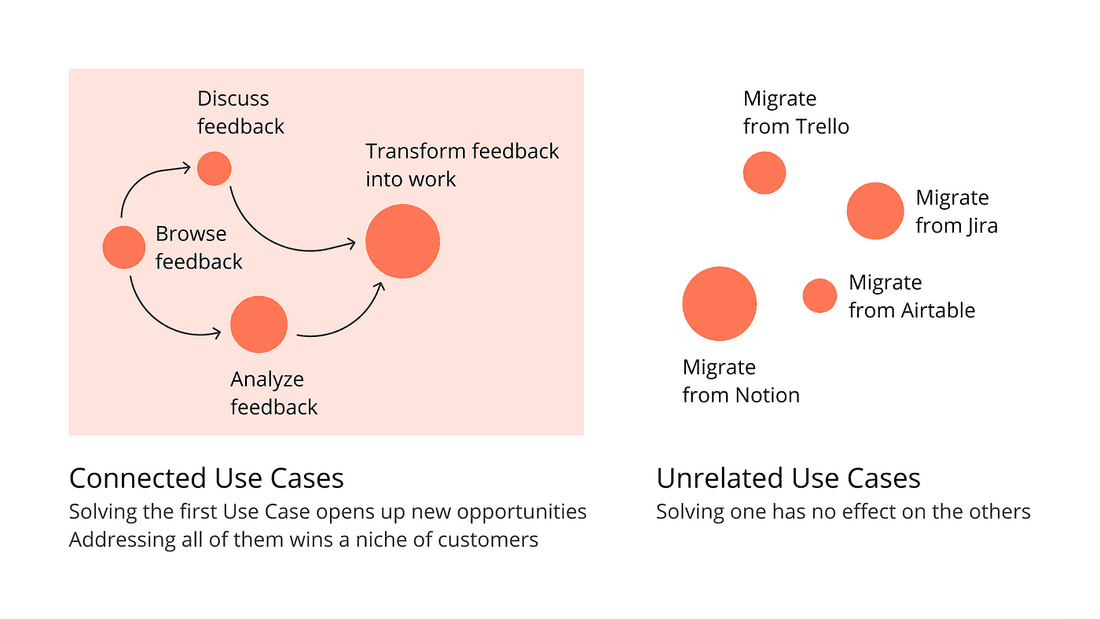
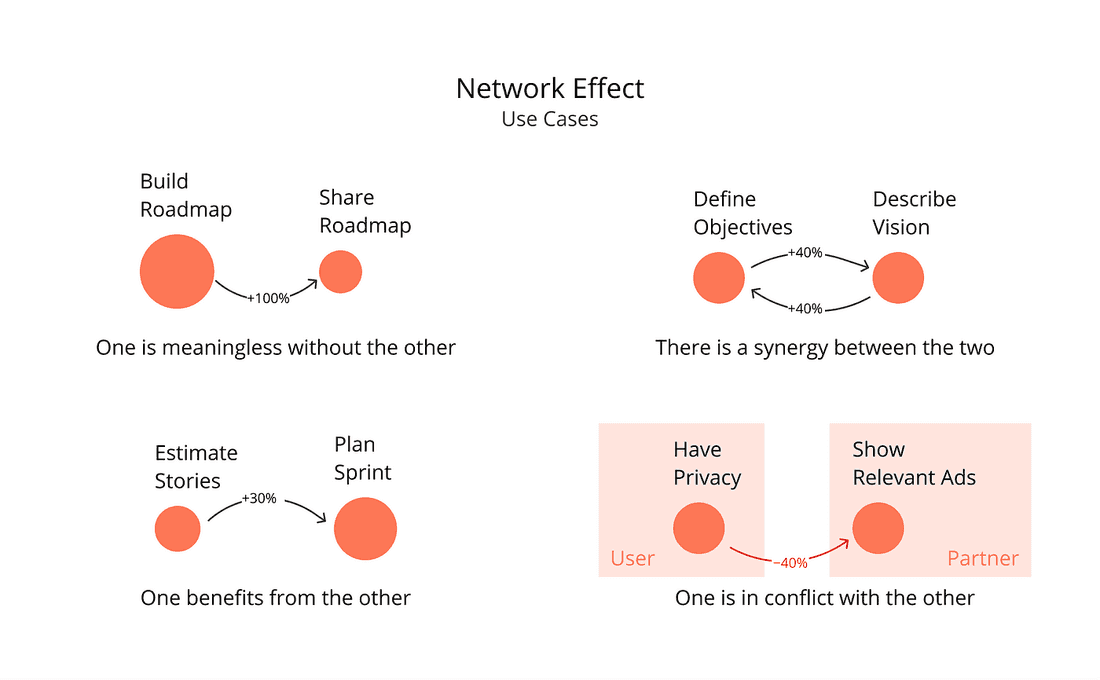
**How connected are the Use Cases? **Solving a bunch of unrelated Use Cases means building a product for everyone and no one. Most often than not, this is a bad strategy:
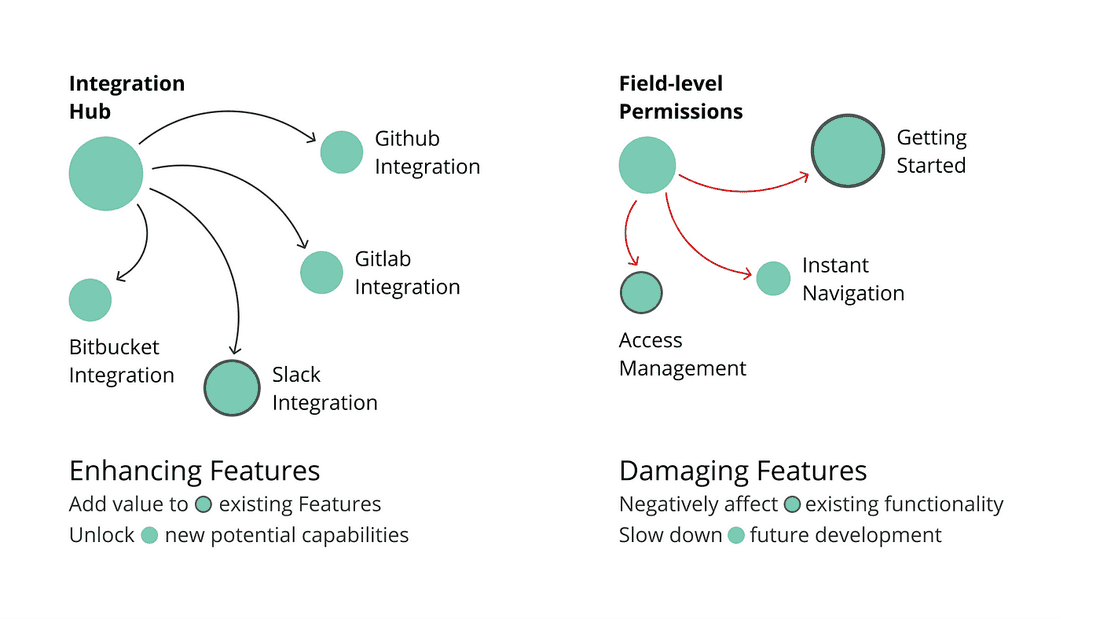
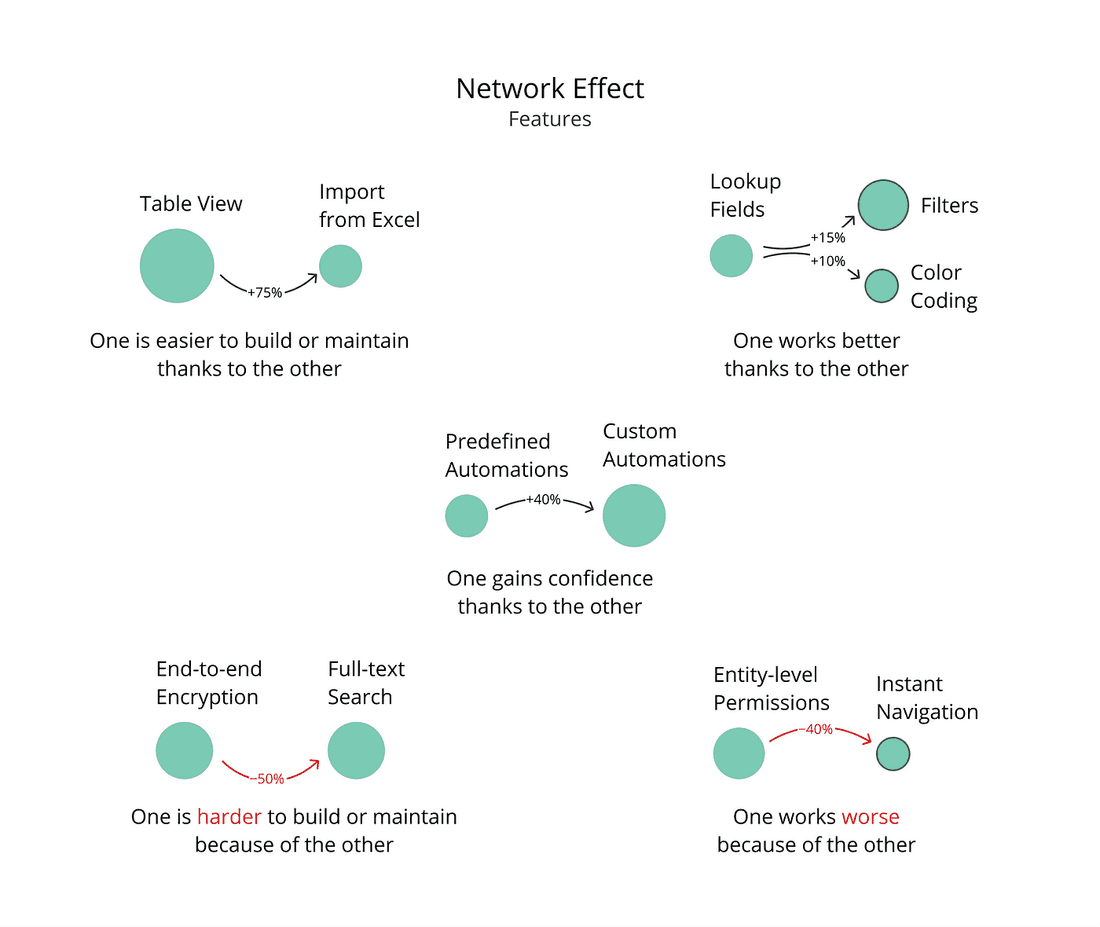
How does the Feature affect other Features? Some Features open new possibilities and enhance existing functionality, others add complexity and slow the development down:
With these two questions in mind, let’s take another look at our alphabetical Features:
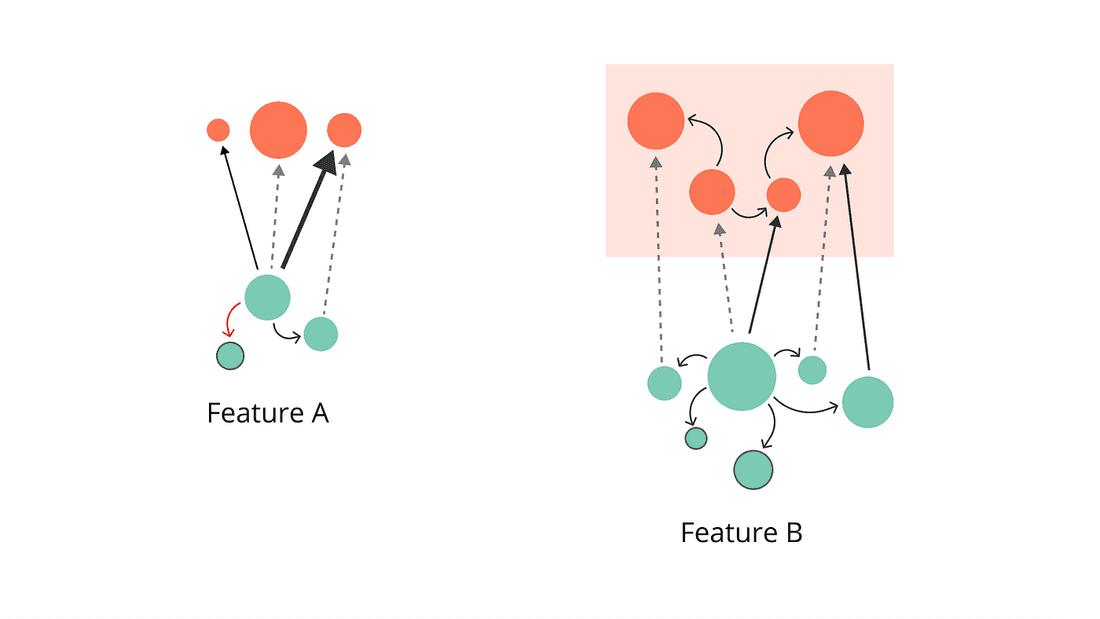
Feature A doesn’t look so good anymore — it would have been a shame to build it first.
Wonder why you often want to override the priorities determined by the formula? It’s because the prioritization formula is short-sighted. It doesn’t know that addressing this small Use Case will greatly contribute to your strategy. It doesn’t know that building this seemingly unimportant Feature will serve as a foundation for something bigger.
The good news is, you can teach the formula.
How to incorporate networks into prioritization?
The goal is not to replace but to enhance the existing prioritization techniques. Let’s start with a simple formula and make it more complicated nuanced step-by-step.

Step 1. Break down the vague “Value” into pieces that facilitate discussion: Reach, Impact, and Confidence. All the Use Cases that the Feature addresses contribute towards the score:

Let’s compare the actual RICE scores for our favorite Features:
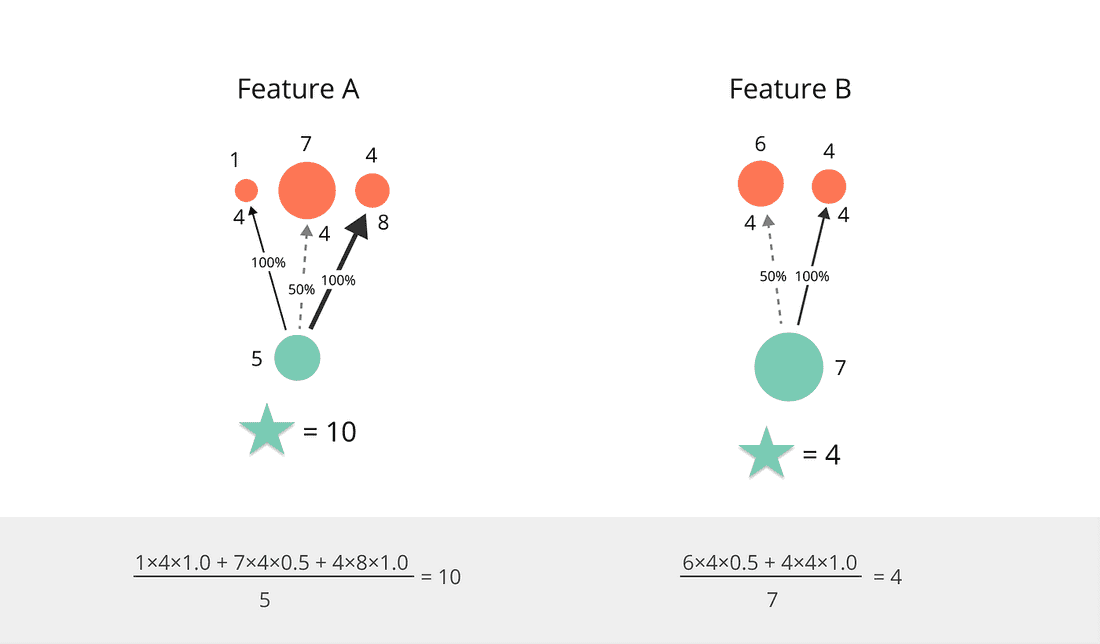
Feature A is indeed a clear winner. For now.
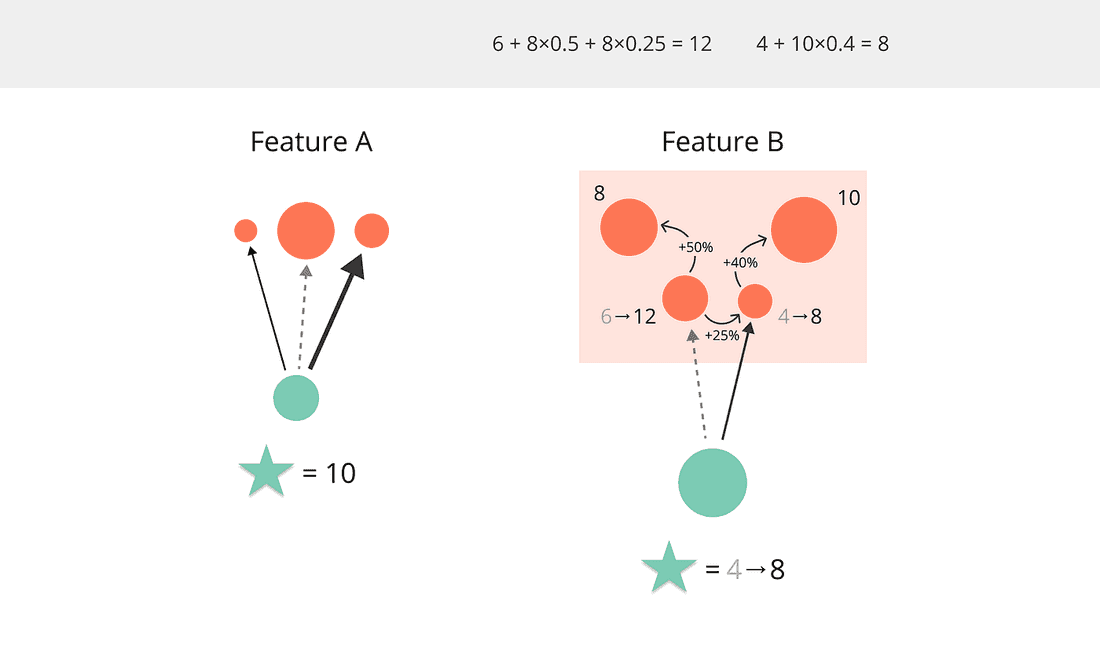
Step 2. Incorporate Use Cases network into the formula. The importance of a Use Case is composed of its isolated value plus its network effect:

🤓 When calculating the network effect for Use Case A, measure the ★ scores for other Use Cases excluding Use Case A from the network. Otherwise, a cyclic graph will eat your computer.
Use Cases that have a great effect on other important Use Cases get a boost. Unlike in PageRank, we count the outbound, not the inbound relations:
Here’s how the scores change with the new formula:
Okay, we are getting closer to reality. Let’s take one last step.
Step 3. Incorporate Features network in the same way:

The Feature is rewarded for enhancing other Features and penalized for negative side effects on the network:
Let’s compare our good old pals one last time:
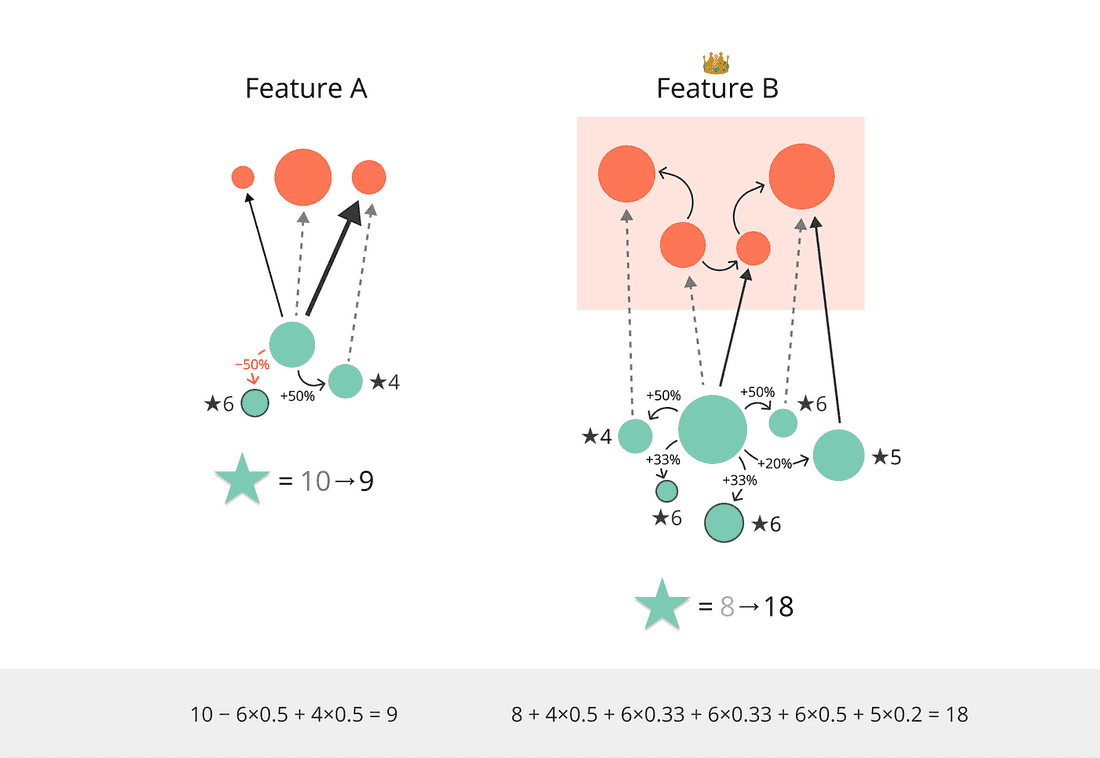
We included only 1st-level connections here — the effect of the whole network will be even greater.
Feature B drops the mic 🎤
As you can see, using networks for prioritization is not just a wild fantasy — it’s both effective and practical.
Are there unexpected bonuses?
Glad you asked.
Once you include networks into prioritization, dependencies are resolved automatically. The foundational Features get a higher score and are implemented first.
If you want to focus on a specific niche or persona, just put a 2x multiplier before the relevant Use Cases’ reach. No need to override the prioritization formula to stay in sync with OKRs.
Do product management tools support this?
Not yet.
Work management tools cannot interactively visualize networks of real data. Hopefully, we’ll see graph views appear in productivity software next to boards, tables, and calendars. We are making baby steps here at Fibery.
Visualization aside, most tools fail to capture attributes of a relation. When connecting a Feature to a Use Case, we need to define impact and confidence. When building networks of Features and Use cases, it’s important to capture the strength of connections. Auxiliary tables in Coda or auxiliary Databases in Fibery is the closest you can get so far. However, without proper visualizations, the experience is just bad.
Once any tool solves these two problems, I will be happy to build and share a prototype. Stay tuned!
Thanks to the Fibery team, Tanya Avlochinskaya, and Ilya Tregubov for thoughtful comments.
Psst... Wanna try Fibery? 👀
Infinitely flexible product discovery & development platform.