How to Estimate Software Development Time
There are many frameworks, ideas, and concepts online about how to estimate software development time. A quick Google search for the best methods to do just that will leave you with many conflicting ideas and questions. Should I top-down, bottom-up, T-shirt size that, planning poker this, or just pull these numbers from the abyss and hope for the best?
But ask yourself: Can you trust these methods with such vital responsibility? Failure to estimate the right way means you might deliver late or rush the finished product. Either way, you are going to look like an ignorant clown 🫠 (not the effective product manager), and neither your users nor your CEO will be overjoyed.
You need a valid solution (or two) that you can trust. This article will show you how to estimate time for software development accurately (er … well, as much as development teams realistically can).
How to estimate software development time
Not every method will let you down (except for planning poker). Some of them can be powerful frameworks, but (and this is a massive but) for most of them to work, you need some form of strong historical validity for them to be data-driven estimates. If you have that, you can rely on the methods listed below.
In cases where you don’t have much historical validity or are under pressure to make estimates on the spot, you can use the 2X estimate approach created by Michael Dubakov, the CEO and founder of Fibery.
2X estimate (good for on-the-spot to medium-term estimates)
With over 15 years of software product development, Michael formulated a rule of thumb: any feature requires two times (hence the rule’s name) as long as initially estimated. This rule works for teams with tons of (or at least some) experience, and it doesn’t require a lot of historical data or excessive planning.
Very inexperienced teams often require about three times as long, so a 3X estimate works better for them.
The 2X rule applies at the level of features, major releases, or any decent chunks of work, but it lacks clarity when it comes to massive undertakings.
Thanks to this rule, you can stop making vague promises. You can forecast the time needed for development and multiply the forecasted terms by the required coefficient.
WBS (best for massive projects)
A work breakdown structure is a great tool for estimating the scope of work and is useful for large projects. However, you need a fairly good idea of what the entire project entails, so you can’t use it for on-the-spot mid-sprint estimates.
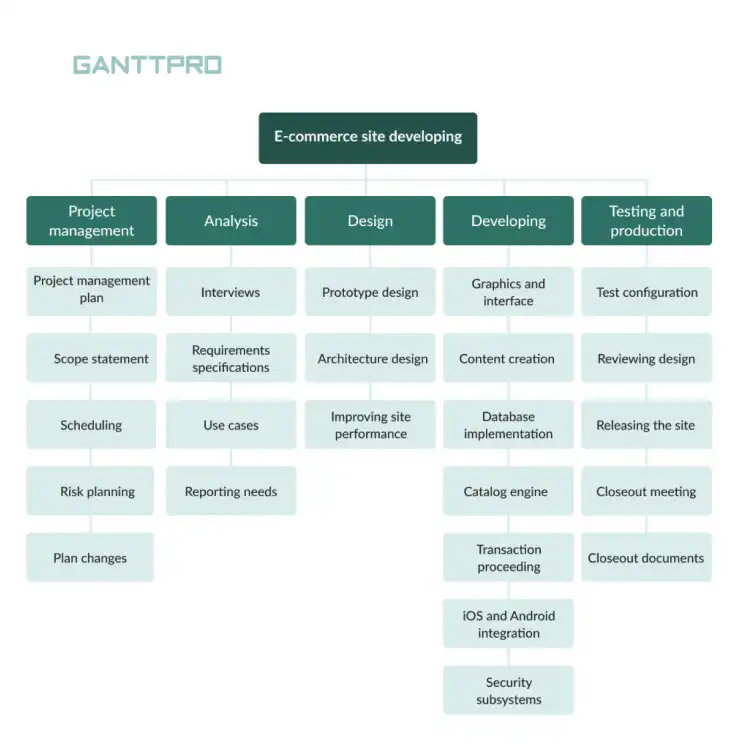
The beauty of using this technique is that you can accurately map what has to be produced during the product’s lifecycle. To do this, you must create a plan encompassing analysis, design, implementation, testing, and maintenance of each little thing you will deliver, and estimate the effort it will take. The more specific the information you detail about the tasks, resources, and results in each stage, the more accurate your estimate will be.
Top-down estimation (good for recurrent tasks)
Top-down estimation takes a more macroscopic approach. It starts with a general overview of the project and effort or duration for the whole banana, and then divides it into its chief components. The estimated relative percent for these significant parts is calculated and combined to determine the project’s total time frame. Therefore, you don’t need massive amounts of data. Of course, you don’t HAVE massive amounts of data.

Compared to the bottom-up method, this technique usually takes less time. To estimate, not to do.
But what happens under the cap of this reasonable approach? You either disregard the uncertainty factor altogether or heap the burden of inaccuracy on your development process – either way, it’s unlikely to be optimal.
Why is it difficult to accurately estimate software development time?
Estimating things like effort and time is hard for many reasons. Sadly, it’s not something taught in school, university, or via boot camps, and spare us the long videos. So an estimate is a wild guess that improves with age, and is sometimes close. And then there’s the problem with the dynamics of the software development life cycle and the users they work so hard for.
For starters, once an estimate and target delivery date is given, they’re often treated like they are set in stone. Unless you have a contract with flexible delivery conditions, you’re basically shooting yourself in the foot and setting the estimates up for failure. Both of those hurt. A lot.
Many customers who have had poor experiences with software development are often skeptical and may try to micromanage things like schedules. Clients breathing down your neck like this also isn’t an ideal way to start things.
Issues like changing product requirements, bugs, overestimating team abilities, or skipping the discovery phase make estimating tricky. Erik Bernhardsson, founder of a data infrastructure company, has two methods for estimating: (a) breaking things down, estimating the pieces, and adding them up, and (b) a “gut feeling estimate based on how nervous I feel about unexpected risks”. So far, he says, (b) is way more accurate for anything but small projects.
Given the fluidity of most kinds of software development, most teams religiously stick to Agile approaches.
However, Agile techniques offer little to no guidance for time and effort estimation. For example, the planning poker technique only causes an experienced developer to burst with laughter (which you have to hold back if a scrum master is present). Seriously, the team gathers for a sprint planning session, the product owner reads them a user story, and they’re required to give it a good three minutes of thought and produce some decent estimation in conventional units based on instinct. Well, godspeed to you!
In addition, it is challenging to comprehend the reality of a project before starting it. So you start with high uncertainty.
That’s why if you want to predict better, you need to get to work straight away and eliminate uncertainties one by one. In Extreme Programming, this is called “spikes.” If, after several spikes, the solutions to all the complicated problems become somewhat clear, the general quality of your assessment improves. Of course, doing anything for real removes uncertainty about it (unless your boat is sinking).
How to use Fibery for software development time estimation
Within Fibery, you can access previous projects with time references to help give an estimate of how long something will take. If you have a project going down the same route, use this as a good baseline, but add some tolerance by providing a range (-25% or +25%).
For example, if you have data on an app that took 400 hours to complete, you can add a range of -25% and +25%. You’ll then have a time estimate of 300 to 500 hours.
Another option is to use the AI in Fibery and no-code capability to add an estimation database, with fields and calculations. Identify the fields you want in it (for example, date and hours), and then connect that to the product or software development hierarchy you are working on. You can link each feature, task, and project to this board, and it will give you an opportunity to estimate effort, duration, or whatever else you might want to estimate.
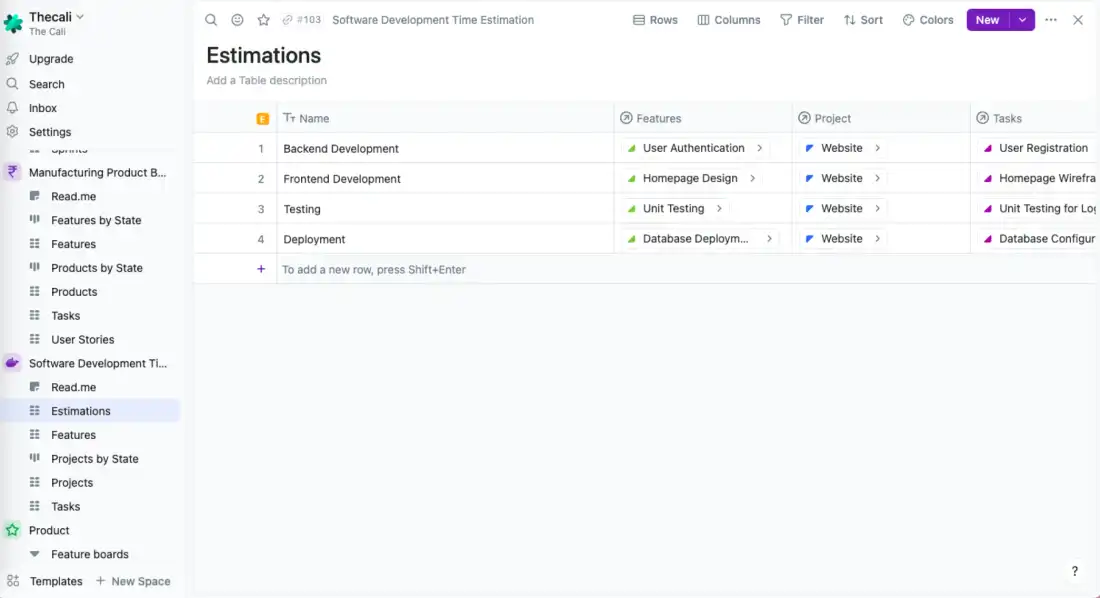
With Fibery, you’ll already have a product backlog, feature board, and sprint backlog for each product. This means you simply connect the work items from them with the estimation database and make your (well-informed and of course totally accurate) estimates from there.
The PM’s hot take
The beginning of a task is the worst point for estimating. At that point, we know too little, while gaining additional knowledge is the only way to improve your estimation. The more we know, the more accurate software development time estimations we produce. That’s why if we want to predict better, we need to get to work straight away and eliminate uncertainties one by one. In Extreme Programming, this was called “spikes.” If, after several spikes, the solutions to all the complicated problems become somewhat clear, the general quality of our assessment improves.
Since most teams try to estimate the required time for development without doing spikes or prototypes, the 2X estimate is a perfectly acceptable error. There’s no way around improving the quality of predictions by accessing the problems only hypothetically, that is, without getting your hands dirty with real work.
Estimating software development time doesn’t have to be rocket science
Providing reliable estimates without strict and clear data comparison or accurate software development estimation techniques is difficult.
With the 2X estimation technique, you can give yourself and your team the room they need to make mistakes, learn, and adapt to changes while doing your best to avoid disappointing your customers. If you have clear data or historical numbers to back up your new product or features, use those while giving yourself a safe range.
You can also rely on Fibery to simplify any estimates you need by adding any formula you want to estimate development time, and then track actual metrics. Try it out today with a free trial.
Psst... Wanna try Fibery? 👀
Infinitely flexible product discovery & development platform.
More gems from our Radically Honest Blog:


How to Write Beautiful Feature Specs in Fibery
Feature spec should be inside Feature, not some other external tool. This article explains specs creation tips and tricks for product managers.

The Definitive Guide to Productboard Alternatives in 2023
Yes, Fibery is a good alternative. But there's a plethora of other options. Hop on the train and sift through all the product management tools that can serve as Productboard replacements.
![Be different [23/100]](/blog/static/64355cda924c61c299f2978da5ba6d31/0fe7f/be-different.webp)
Be Different [23/100]
Living organisms can coexist in the same area if they are different enough. This applies to markets and products as well. If a product is similar to others on the market, prioritize unique features to differentiate it and carve out a niche.
![5 Biggest Problems in Software Development [22/100]](/blog/static/08512600f4074191672f6e4b07557f7f/f5b68/SoftDevProblems.webp)
5 Biggest Problems in Software Development [22/100]
Whine with me about the biggest problems in software development. From user satisfaction to more profound issues, let's discuss it.