The Knowledge Organization
In a creative organization — tech startup, management consultancy, law school — Henry Ford’s productivity is much less relevant than Douglas Engelbart’s collective intelligence.
Instead of looking for ways to “boost productivity”, we wonder how we can augment collective intelligence. Here are our goals as Engelbart put it:
- more-rapid and better comprehension
- gaining a useful degree of comprehension in a situation that previously was too complex
- speedier and better solutions
- finding solutions to problems that before seemed insoluble
In a series of joyfully boring essays we are going to explore ways of achieving these goals. Maybe, some ideas will even find their way into Fibery’s vision, who knows.
So where should we start?
Knowledge Architecture
At the basic level, it all comes down to capturing, sharing, and generating knowledge. So the first step is to get this knowledge out of bright heads and into a shared space.
How should this space look like? Good old files and folders? Powerful databases? Trendy networks?
In this article we are going to explore five different approaches to knowledge architecture in an organization. We are looking for the most natural structure that encourages people to discover and share knowledge. The structure should help us to build on top of each other’s ideas.
Starting with…
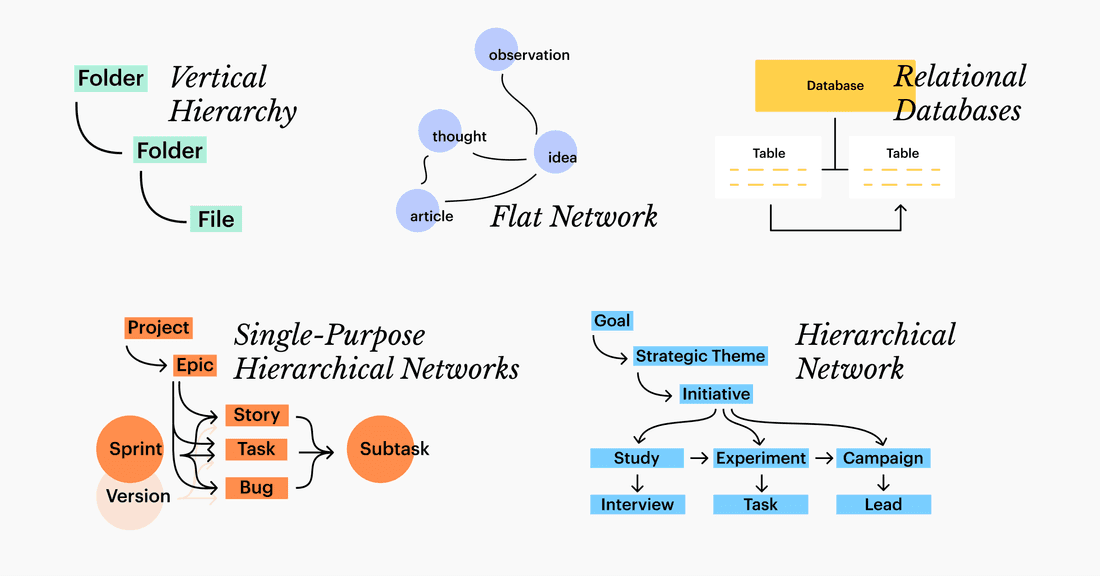
Vertical Hierarchy

The most ubiquitous structure is a strict vertical hierarchy.
Some bearded guys borrowed the file cabinet metaphor in 1960s, and it has become a standard since. From cloud drives to note taking and work management tools — it’s all folders and files in some shape or form.
💎 The onboarding is easy. With the ubiquity comes familiarity — you don’t need to explain to anyone how folders work.
Unfortunately, popular ≠ the best. The strict hierarchy made sense in the real world: a book can only be on a single shelf in a particular room. However, the restrictions of physical objects should not apply to abstract knowledge.
💩 Every entity has to be exactly in one place. Two teams collaborating on the same project? Let them decide where the project goes in a vicious pillow fight:
In our examples we will pretend that all organizations build digital products 🤷♀
Alternatively, duplicate the data and hope that the intricate two-way sync won’t suprise you with a merge conflict any time soon.
💩 The organization has to agree on a single hierarchy for all purposes. Business folks want folders to be initiatives, engineering folks — product areas. Let them decide in a vicious pillow fight:

And once they decide, there is no going back because…
💩 Evolution is near impossible. A company is transitioning from outsource (folders = clients) to product (folders = products) development? The next few months will be fun!
Speaking of fun — what about cross-team collaboration?
💩 Horizontal connections are lost. Try mapping this natural workflow into a vertical structure:
The vertical approach produces inflexible information silos. As Ted Nelson noted in the legendary Computer Lib/Dream Machines:
Hierarchical structures are usually forced and artificial. Interwingularity is not generally acknowledged — people think they can make things hierarchical, categorizable and sequential when they can’t.
So let’s… acknowledge interwingularity?
Flat Network

In a flat network we are free to form arbitrary connections between nodes (pages).
In a good network, these connections are bi-directional: if two pages are related, we’ll always see the connection on both of them. Unfortunately, this is not how most networks work — yet 🤞.
Lately, we’ve seen a revival of the “networked thought” fueled by the idea that…
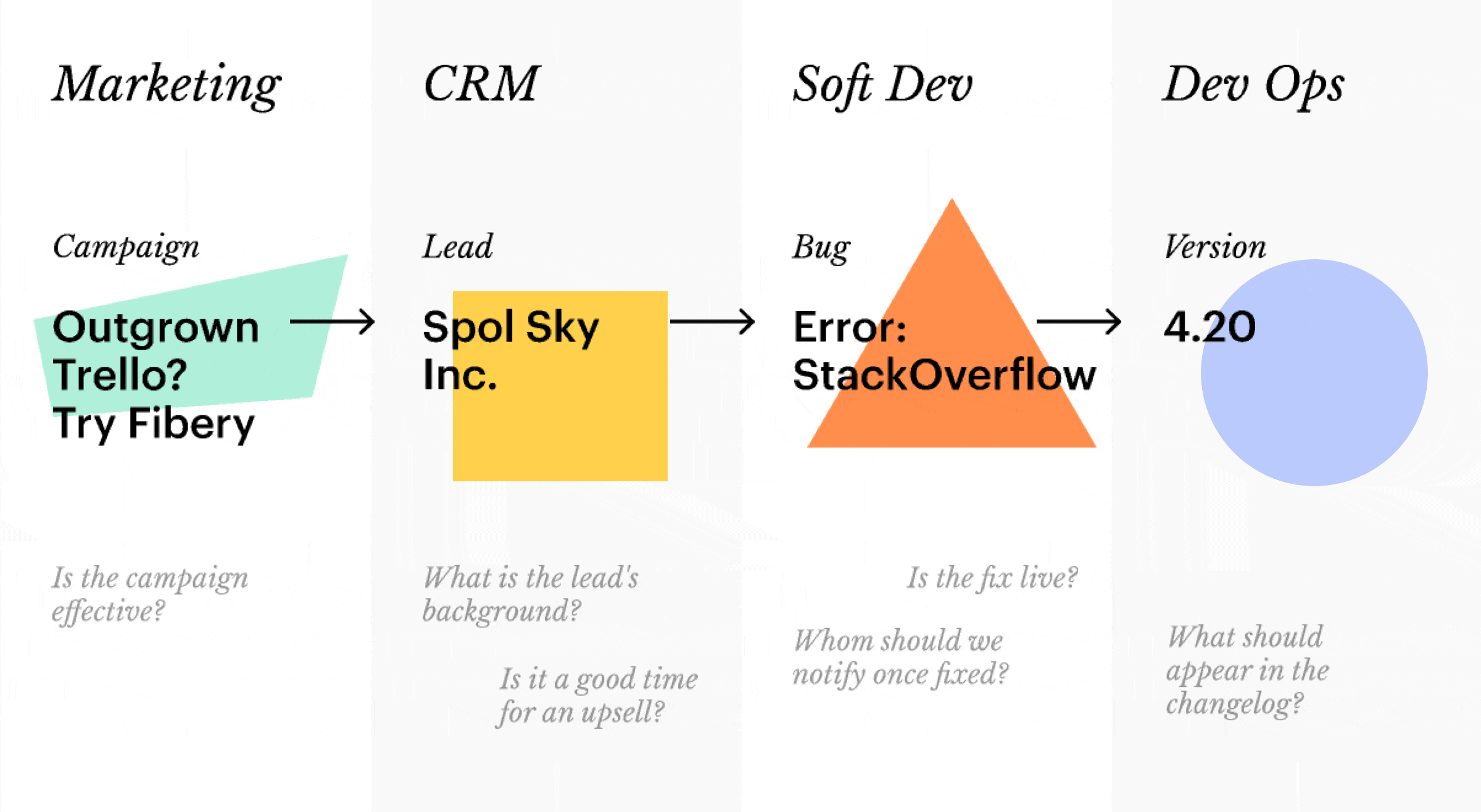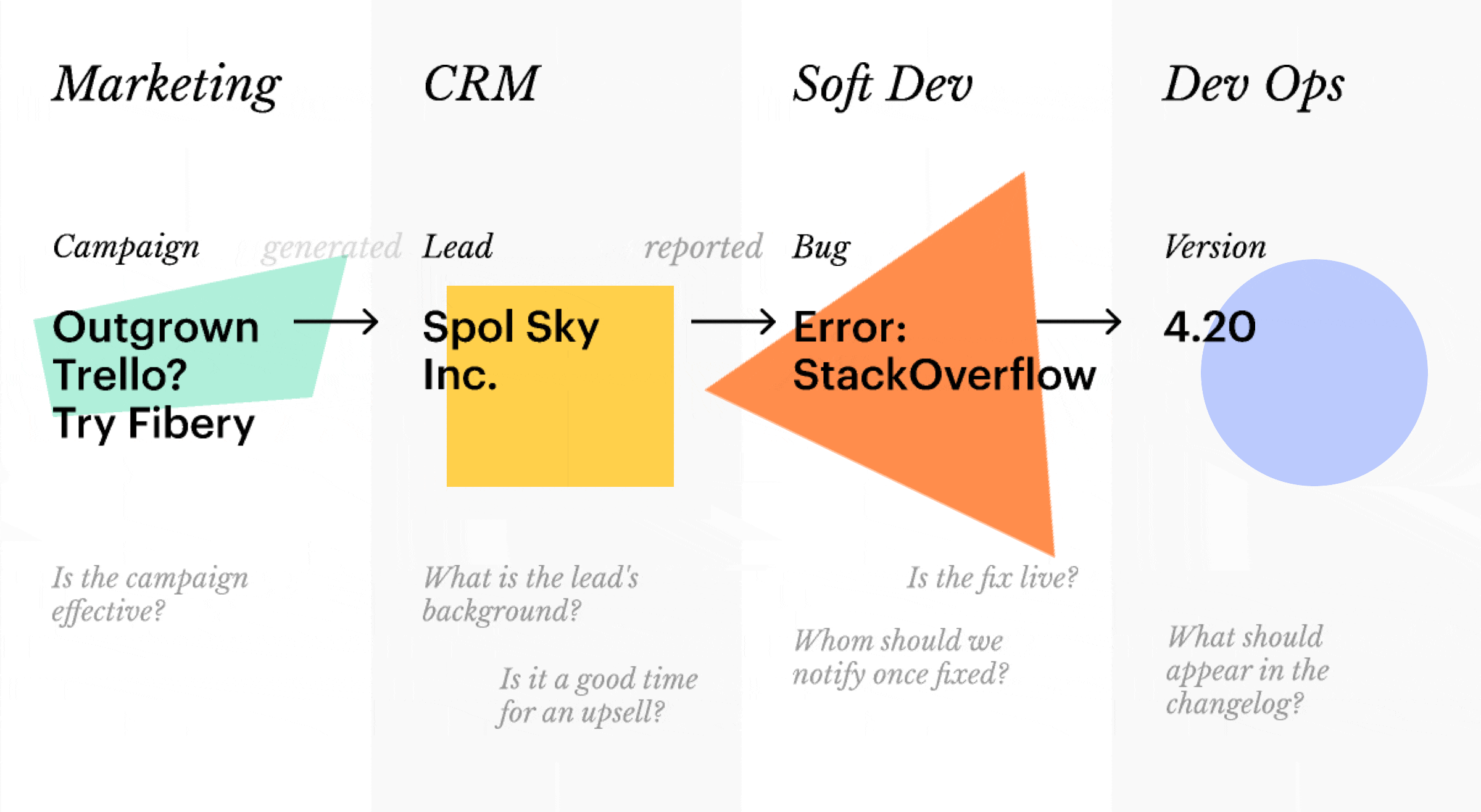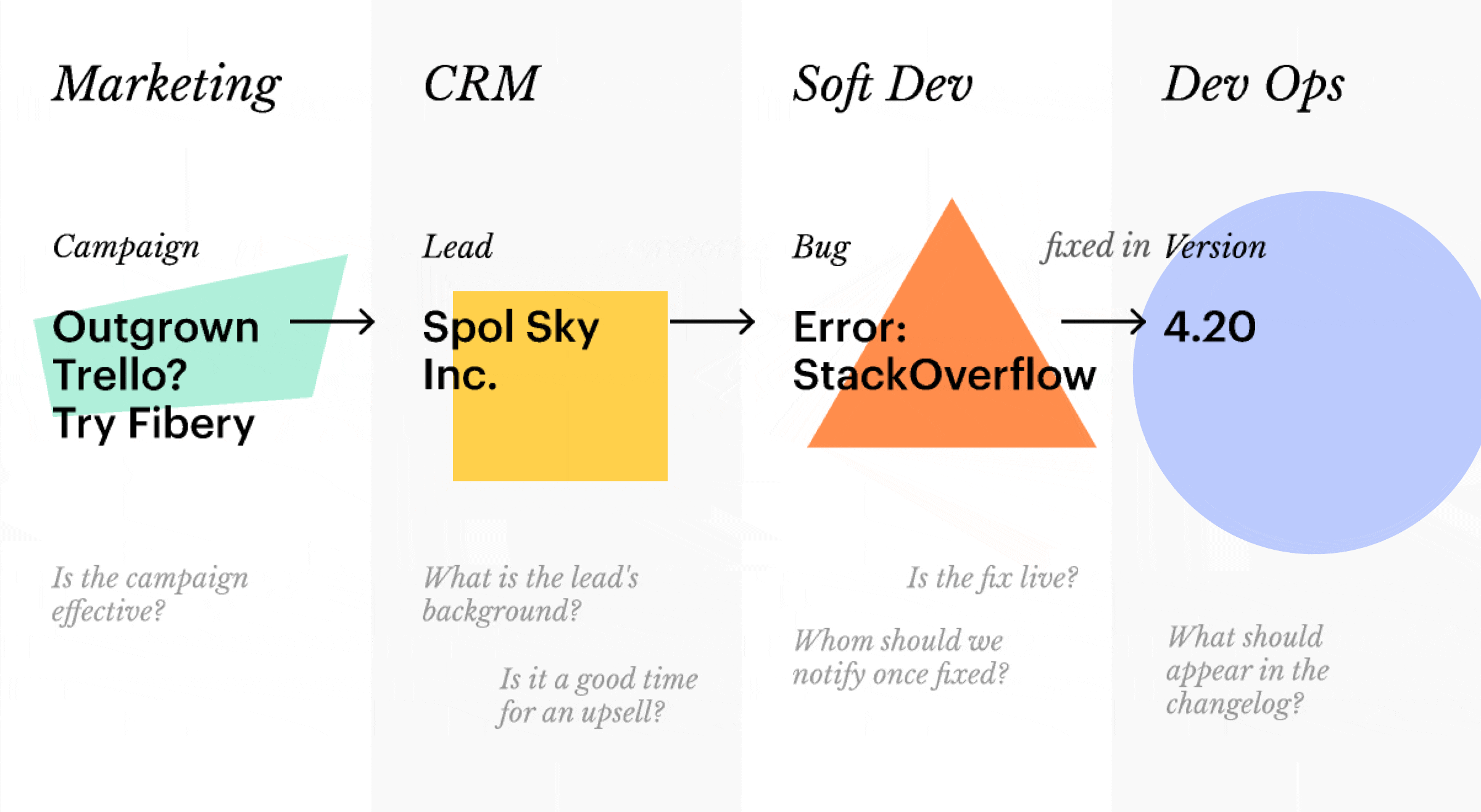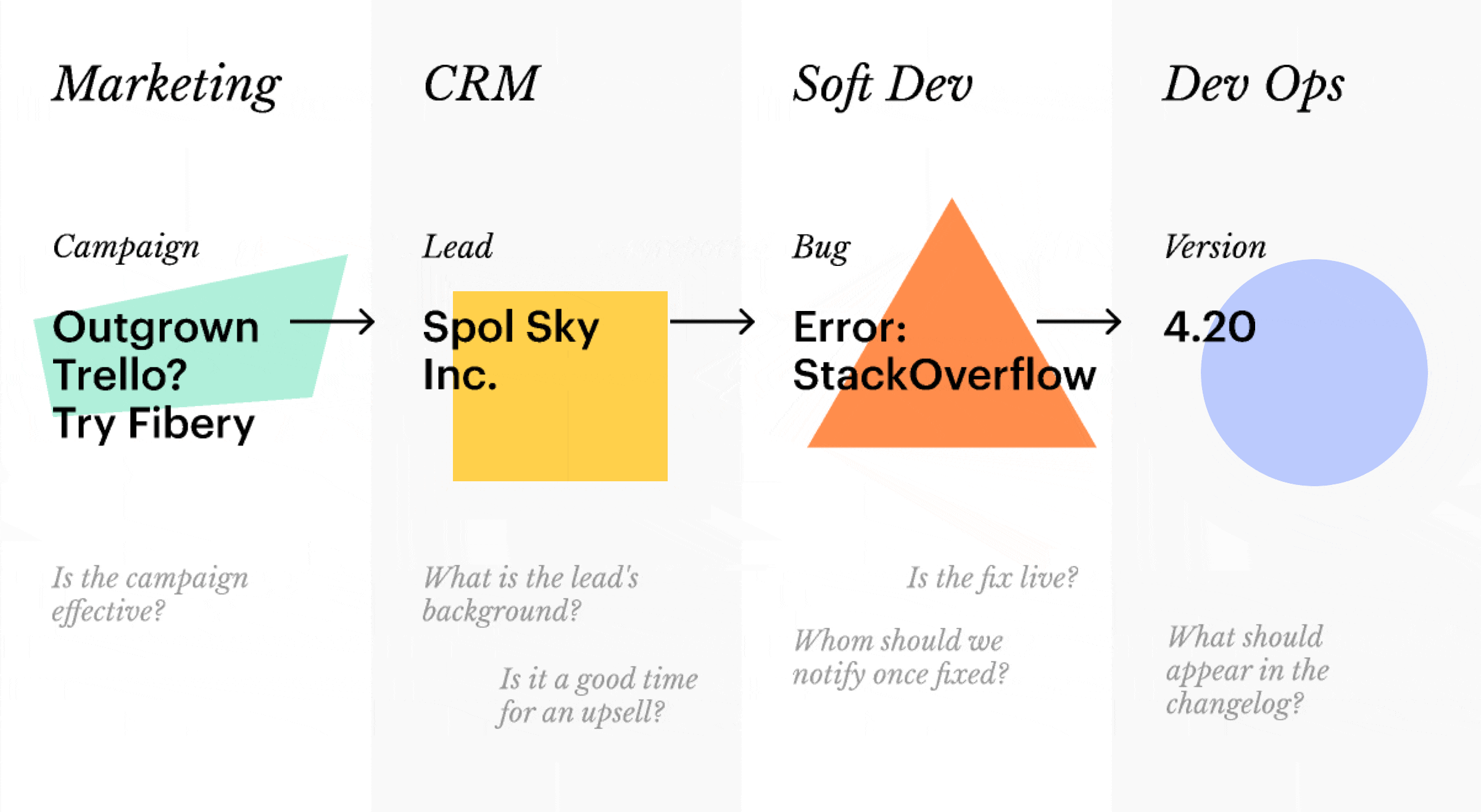
💎 Free associations are closer to how brain works. Thoughts are not neatly packed in file cabinets: rather one leads to another and yet another. In a flat network this means that the “campaign → lead → bug → version” workflow we mentioned above works like a charm.
💎 Knowledge naturally accumulates. There is no limit on the size of the network and no restrictions on how it should grow.
Just like our brains, flat networks are great at working with unstructured knowledge but suck when it comes to structured data.
💩 Querying data is hard. All pages have either the same or unpredictable attributes. Getting all high-priority features or all customers due to renew the next month is nearly impossible.
💩 Visualizations are limited. Most vizualizations rely on structured data — so forget about a Kanban board with swimlanes, an event calendar, a gantt chart, or a hierarchical list.
💩 Repeatable processes are undiscoverable. Since there are no required (or even desired) attributes and relations, there is nothing to nudge folks into a predictable workflow. You have to explain each newcomer that “we decompose Epic into Stories, estimate these Stories, and plan into Sprints” — a flat network cannot guide them.
So we need both horizontal and vertical connections as well as the ability to handle structured data. Sounds pretty much like…
Relational Databases

In a relational database, both vertical and horizontal connections are present through one-to-many and many-to-many relations. Each table has its own attributes making home for structured data.
💎 The structure is flexible. The knowledge architect is free to create as many or as few tables as needed and connect them in the way it makes sense to the particular organization. As organization evolves, she creates more tables and adds more relations.
A common pitfall is to design a database that doesn’t satisfy at least 3NF and struggle with complicated queries and data duplication.
💩 Building a database requires time and skill. This is the price your pay for the flexibility. While Airtable has democratized online databases, the knowledge architect still has to understand how data normalization works — at least intuitively.
💩 It’s either one unmanageable, or many disconnected databases. When all teams share the same database, it quickly becomes huge and messy. When teams split into several bases, it’s “hello” to information silos and “bye” to cross-team collaboration. Instead of sharing data, it’s all back to pillow fights — where should the customers table go, in sales or marketing db.
On the bright side…
💎 Pretty much any visualization or query is possible. Tables, boards, charts, and even maps — with data filtered and sorted as you desire. If a database doesn’t have a visualization out of the box, you can usually build one.
While the structured data feels at home…
💩 Unstructured knowledge is not welcome. Collaborative documents, whiteboards, and multimedia are second-class citizens at best and are simply missing at worst.
Is there a way to combine structured and unstructured knowledge, vertical and horizontal connections?
Single-Purpose Hierarchical Networks

Most single-purpose work management tools are, basically, hierarchical networks. Tool vendors understand they need the best of all worlds to foster collaboration.
💎 Structured and unstructured knowledge is mixed. You set feature priority, but you also write specs. You advance deals through a pipeline, but also take meeting notes. Hopefully, digital whiteboards and interactive embeds will also be welcome — one day 🤞.
💎 Multiple parallel hierarchies coexist. A Task belongs to a Sprint, but also to a Version and a Component. A few pillows saved.
💎 Visualizations are tailor-made to specific workflows. If a team adapts its behavior to the tool, it’s rewarded with a top-notch user experience.
Wait, but what if a team is happy with its habits and doesn’t want to kneel before the tool? That’s the catch.
💩 Single-purpose is synonymous with inflexible. A team has grown, and you need an extra level of hierarchy — 🤷♀️. You call it Deals, not Opportunities — 🤷♀️. Haven’t yet settled on a process and are experimenting with workflows — 🤷♀️. Want to look at the data from a different angle — 🤷♀️.
Teams are diverse so each one gets its own purpose-built network.
💩 Networks are isolated. We are back to information silos, islands of knowledge, bubbles of data, please stop me, idea zoos, insight prisons. Because of the incompatible data models, cross-network integrations are always limited and clunky.

So what can we have instead of many single-purpose networks? A single generic…
Hierarchical Network

Each node in the network is of a particular type (Objective, Customer). Types form hierarchies: Objective has several Key Results, Customer — many logged Chats and a few too many reported Bugs.
A single generic hierarchical network is capable of holding all the knowledge of an organization. So why aren’t these networks common?
First of all, the vertical hierarchy has become a no-brainer default, and we rarely stopped to ask if there might be a better generic storage architecture. This “things have already been figured out” effect has been common across computer science since 1980s. Bret Victor put it best:
Replace “programming” with “knowledge architecture” (29:52—31:17)
Second, there hasn’t been a platform to easily build such networks. Why hasn’t there been a platform? Well, as we have found out in the last 3 miserable years, the platform is damn hard to build — interview what is left of our engineers.
What’s so special about the hierarchical network?
💎 Adapts and evolves with an organization. It’s easy to start with a simple network and create more hierarchies as the company grows and diversifies. Each team constructs its own subnetwork — connected to the wider pool of knowledge.
Here is Ted Nelson again:
The first chapters of Nelson’s Literary Machines are a gem for a knowledge architect.
If you are not falsely expecting a permanent system of categories or a permanent stable hierarchy, you realize your information system must then deal with an ever-changing flux of new categories, hierarchies and other arrangements which all have to coexist; it must be a tolerant system which allows them to cohabit comfortably, helps track their variations and disparities, and is forever ready to accomodate new arrangements on top of those already present.
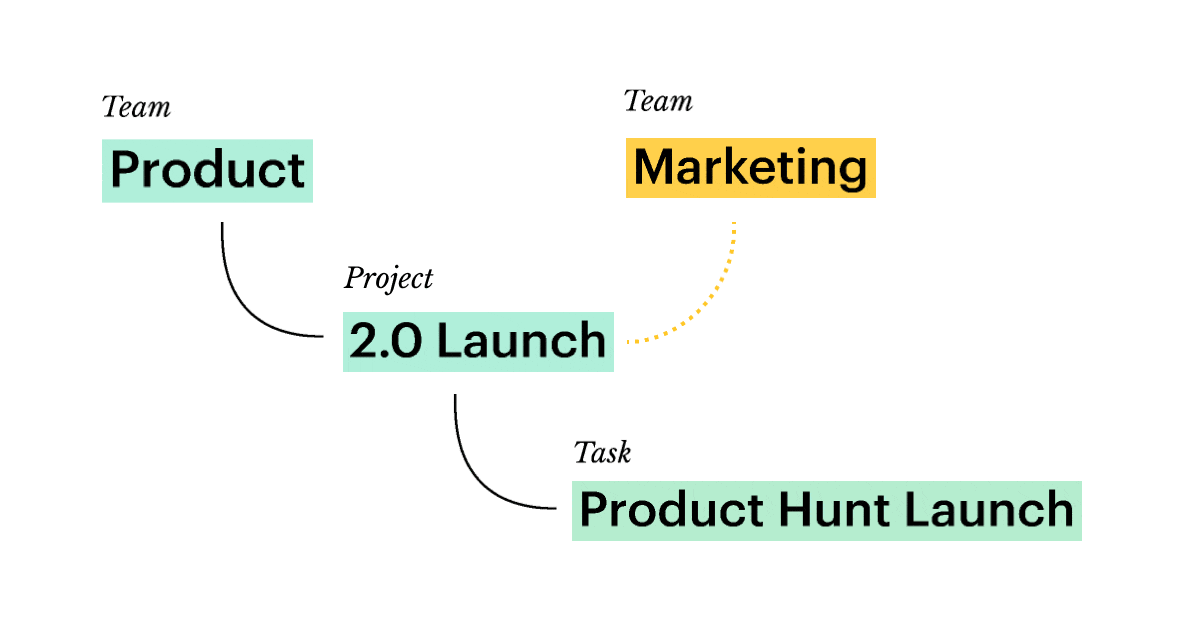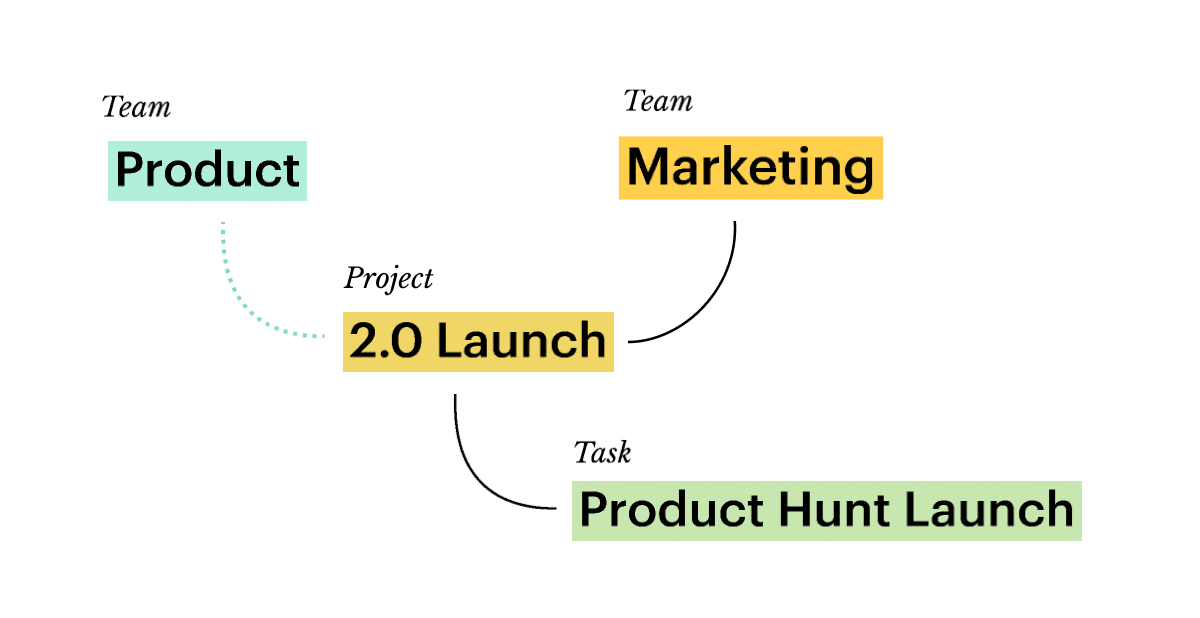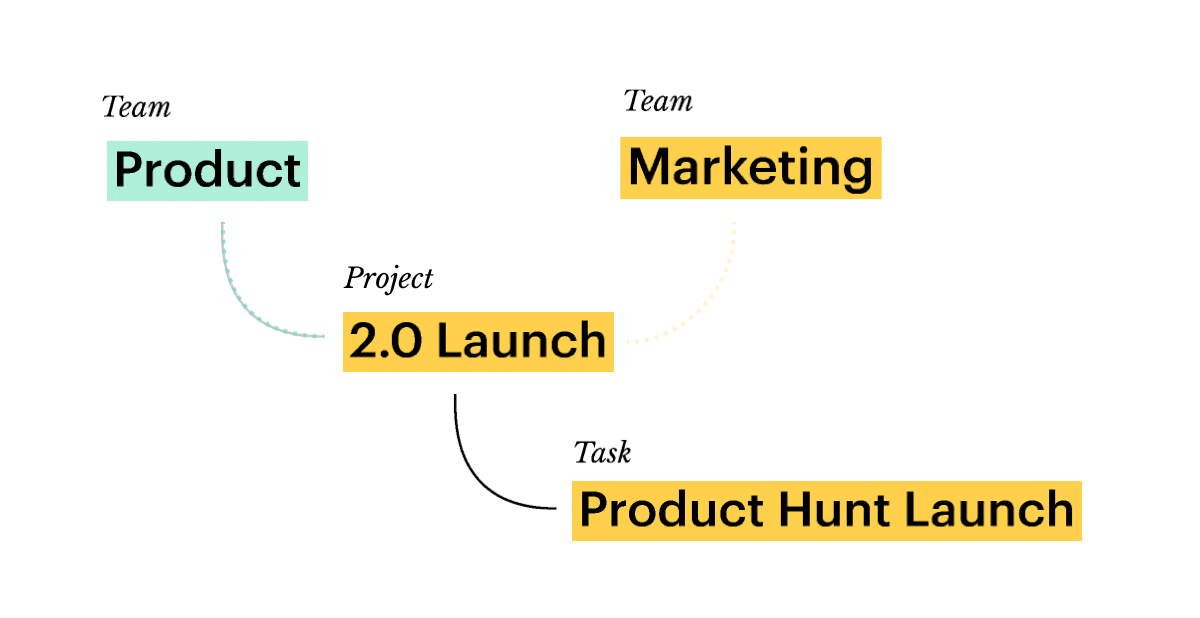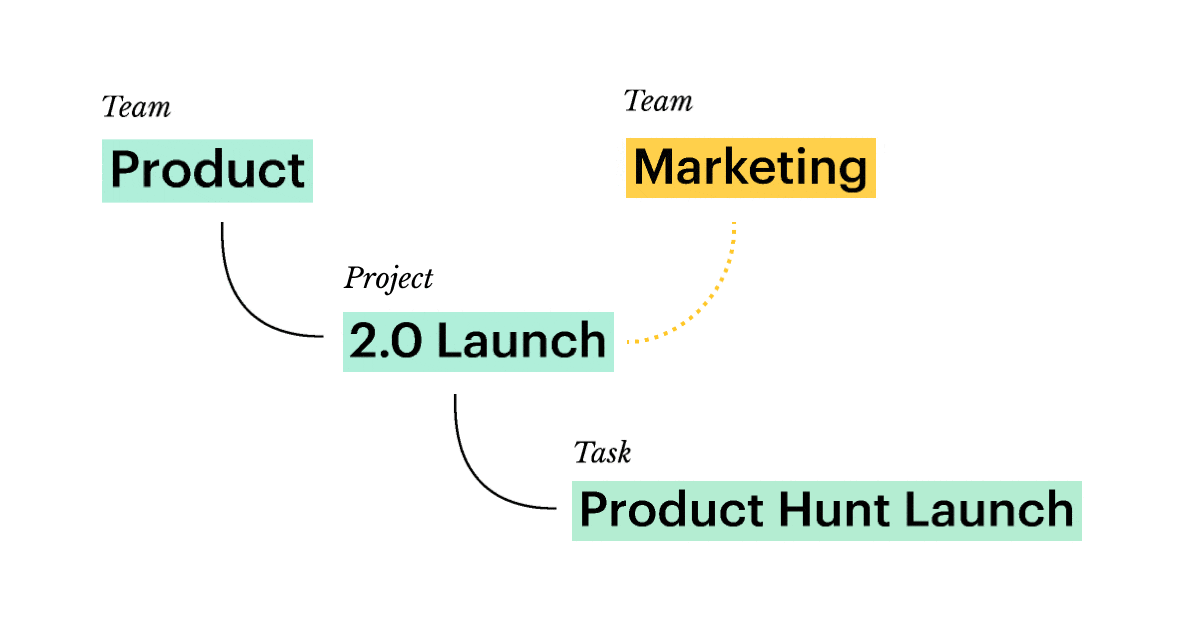
💎 Promotes transparency and cross-team collaboration. With both objectives and tasks present, teams understand their work in a wider context. Unless access to subnetworks is limited on purpose, everyone is free to explore how others contribute to the common goals. Customer-related knowledge is shared between sales and customer success, launch-related — between product and marketing. Horizontal workflows are smooth:

Note: not all horizontal relations are predictable. Campaigns usually generate Leads — thus, Campaign → Lead relation appears in the network. But then you might launch a campaign centered around a particular Competitor once — instead of creating a full-blown relation, you’ll be better off using bi-directional hypertext links.
Each node in the network — an Objective, a Project, an Article — should serve 4 major purposes:
- Database record for structured data: due date, estimate, assignee, status.
- Knowledge hub for thoughts and ideas: docs, diagrams, videos, and more.
- Dashboard for related activities: Initiatives Kanban for an Objective, burndown chart for a Sprint, Contacts list for an Account.
- Discussion room for synchronous (calls), near-synchronous (chats) and asynchronous (comments) communications.
We will explore the node design in detail in future essays. Now let’s leave the “how” aside and highlight the “why”.
💎 Consolidates all kinds of knowledge. Each team member contributes: a product manager describes the research behind the feature, a designer embeds mockups and prototypes, a team discussion happens and the estimates are set, devs attach relevant commits, and QAs write test cases. Everything happens in the same place — facilitating collaboration.

So is this a flawless knowledge paradise? Unfortunately, no.
💩 Requires a new mental model. There is no magical one-click migration of folders and docs to a shiny new tool that suddenly starts “augmenting collective intelligence”. You design a starting network, you realize that a lot of connections are currently missing, you embrace the interwingularity, and form new habits.
💩 Challenges knowledge architects. Designing a network requires abstract thinking. Building an effective hierarchy is impossible without data normalization, connecting subnetworks — without cross-team collaboration.
In the era of the ”no-code revolution”, you would expect more platforms supporting DIY hierarchical networks. However, Notion has gone for a hybrid approach: a vertical hierarchy for the pages, and a somewhat hierarchical network for the databases. Coda is similar — with hierarchical subnetworks clumsily connected via a read-only cross-doc sync.

Check out Fibery vs. Notion and Fibery vs. Coda with real-life (and almost unbiased) examples.
Anyway, we optimistically expect more platforms to pop up in the next couple of years. Meanwhile, you have to put up with Fibery, sorry.
We have endured Fibery since the early prototype ourselves. Douglas Engelbart called it “bootstrapping” — using what we build to boost our own effectiveness. We have grown from 6 to 14 people and here’s our ugly hierarchical network now:

Summary
In a creative organization, work management is knowledge management. The architecture you choose shapes the way knowledge is captured, discovered, and shared.
It’s tempting to stick with Google Drive or OneDrive: you already pay for one, and everybody is familiar with folders and files. But, before you do, consider:
This makes Douglas Engelbart sad.
- Missing context impedes quick and deep comprehension of a problem.
- Separating “work” from “knowledge” harms solutions and slows down the execution.
Another option is for each team to use a specialized tool like Jira or Pipedrive. While achieving a local maxima, this approach hurts organization as a whole. Instead, consider consolidating knowledge in a shared space:
Think competitive analysis with inputs from marketing, product, and sales teams 🤯
- By sharing knowledge, teams gain an unprecedented level of comprehension.
- With diverse roles collaborating, a team invents unexpected solutions.
- Because of cross-team transparency, an organization implements solutions quicker.
Lock yourself in an empty conference room for a couple of hours and think what an ideal knowledge architecture for your organization looks like. Experiment with Airtable, Roam Research, and Fibery. Choose a few organization-wide projects and run pilots. Be brave ✊
Meanwhile, share your thoughts with fellow knowledge architects on Reddit.
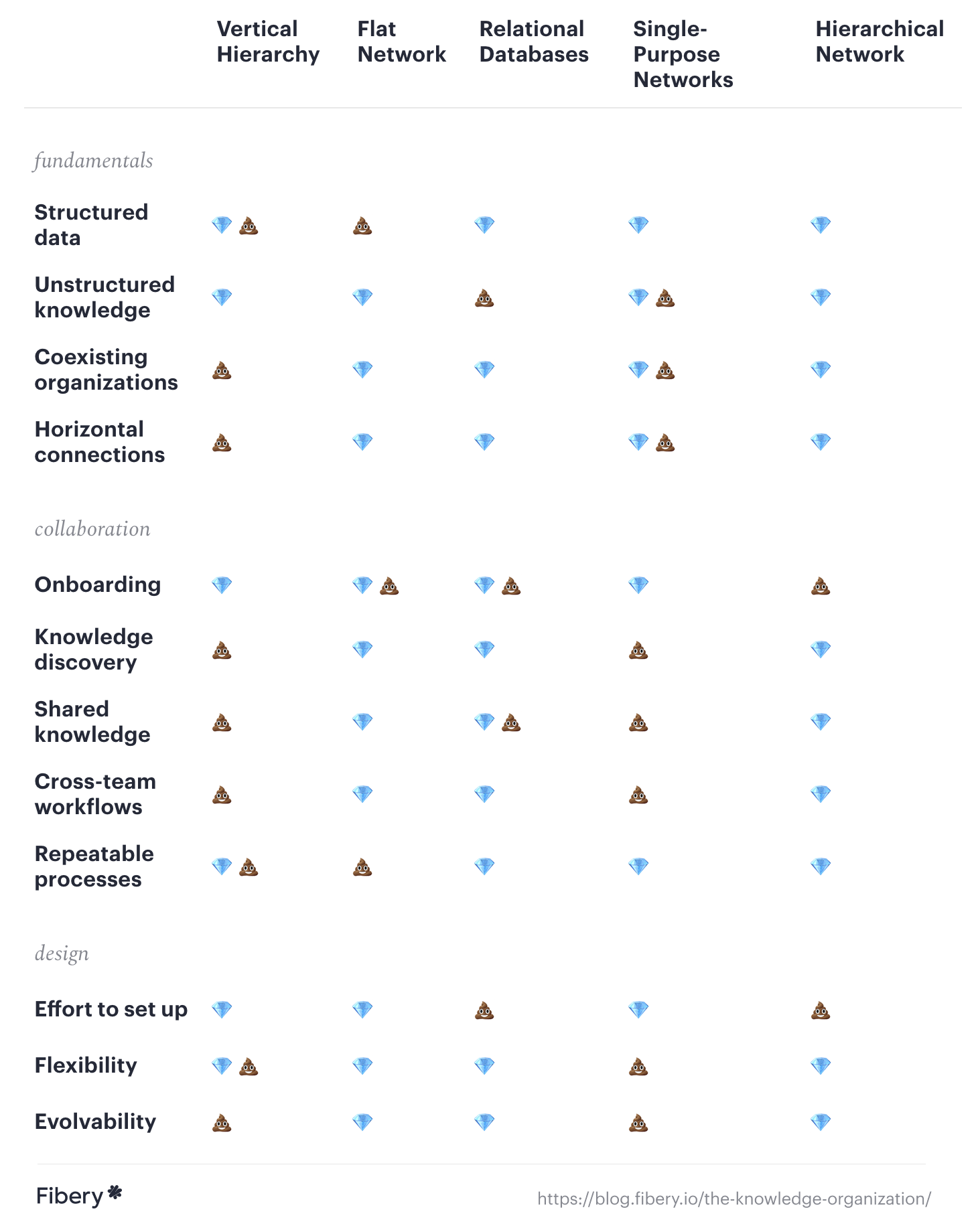
Cheatsheet
| Vertical Hierarchy | Flat Network | Relational Databases | Single-Purpose Networks | Hierarchical Network | |
|---|---|---|---|---|---|
fundamentals | |||||
| Structured data | 💎💩 | 💩 | 💎 | 💎 | 💎 |
| Unstructured knowledge | 💎 | 💎 | 💩 | 💎💩 | 💎 |
| Coexisting organizations | 💩 | 💎 | 💎 | 💎💩 | 💎 |
| Horizontal connections | 💩 | 💎 | 💎 | 💎💩 | 💎 |
collaboration | |||||
| Onboarding | 💎 | 💎💩 | 💎💩 | 💎 | 💩 |
| Knowledge discovery | 💩 | 💎 | 💎 | 💩 | 💎 |
| Shared knowledge | 💩 | 💎 | 💎💩 | 💩 | 💎 |
| Cross-team workflows | 💩 | 💎 | 💎 | 💩 | 💎 |
| Repeatable processes | 💎💩 | 💩 | 💎 | 💎 | 💎 |
design | |||||
| Effort to set up | 💎 | 💎 | 💩 | 💎 | 💩 |
| Flexibility | 💎💩 | 💎 | 💎 | 💩 | 💎 |
| Evolvability | 💩 | 💎 | 💎 | 💩 | 💎 |
Also, grab any illustration from this essay for your blog. We appreciate if you link back to the article.
Psst... Wanna try Fibery? 👀
Infinitely flexible product discovery & development platform.
More gems from our Radically Honest Blog:

{kind=link}

Fibery End Game (Product Company Example)
How Fibery will transform product companies work and knowledge management processes, help them invent better solutions and build things faster 🐌 → 🦉

Group Permissions That Blend Into Collaboration Software
In most products, you'll find permissions on the outskirts, disconnected from the rest of the data — but not in Fibery.

Hypertext Tools From the 80s
The pre-internet era was full of wonderful and very powerful systems that are well forgotten now, but we definitely can learn from them, try to understand why we had an enormous degradation in the 1990s and 2000s, and why we are enjoying hypertext systems renaissance now.

Fibery Approach to Integration
An unorthodox way to integrate Fibery with external systems, like GitHub, Intercom, GitLab, HubSpot, Jira, Braintree and others.