Life After RICE: Prioritize Based on Facts
I always struggled with the question “What to build next?” as a product manager. To me, this was the hardest question to answer. I tried many things, like the Kano model, RICE, my own linear model with many parameters, and gut feelings. I discovered that the gut feelings method works as well as RICE.
But I always felt we could do better.
We invented a better way, and in this article, I will show it to you 🔦.
If you want to know more than what is in this article, join our webinar for practical tips: register for free.
Prioritization and the number of customers
Let’s try to set some context first. There are 3 stages for a company:
- No customers
- Few customers
- Many customers
How do they define prioritization techniques and needs?
Prioritization + no customers
This is the most tricky phase for any company. You almost always make decisions based on intuition (vision is also a part of this intuition). Intuition works fine, but only when you feed it with enough information. Market reviews, competitors reviews, customer discovery sessions, some ad-hoc problems you read on Reddit (so-so) or experienced yourself (best). You have to read and listen a lot. At some point you have an insight, scream “This is it!” and go build it. With luck and a lot of effort, you get a few customers.
Prioritization + few customers
Prioritization with few (target) customers is easy. You just listen to their feedback, understand the most painful problems, and go solve them. When you have dozens of problems in a backlog, it is not that hard to just know that the “we can’t find things in your tool, there is no search” problem was mentioned on every call. You just remember things and usually make the right choices. Eventually, with a lot of effort and luck, you acquire many customers.
Prioritization + many customers
Here, things get tricky again. You have thousands of requests, hundreds of calls, and thousands of conversations in Intercom, and you receive signals from sales, customer success, competitors, executives, and your teammates. You have strategic choices and have to align the whole company. You build huge spreadsheets and try to use some formal prioritization framework, like RICE. You play with numbers, correct impact score here and there, and fix effort till it looks like a believable backlog sorted by priority. But deep down you don’t trust it much and you always ask this question in your head: “Are we working on the right thing?“.
Why RICE is better than nothing?
The RICE framework is a popular prioritization model that stands for Reach, Impact, Confidence, and Effort. It is used to evaluate and prioritize features, or initiatives by scoring each based on these four factors.
RICE is a very popular method, so it must be good, right?
My favorite benefit is nailed by Brian Knauss:
I’ve been using RICE successfully for several years. It is a wonderful tool to fight off prioritization by loudest voice in the room.
Indeed RICE frames discussions around RICE properties, and it can reveal useful information that affects decisions about what is more important. You can argue about something more concrete than just “I’m sure it is the right thing to do”.
Another benefit is that RICE uses some data and pushes to find evidence to back up decisions. While the data is usually hard to get, it is in the right direction.
My personal journey with prioritization models
For reference, my experience is limited to two product companies. I spent 14 years in the first one, and 6 years in the second. Here is a single image that explains it all.
When our company grew beyond 100 people, we tried more formal prioritization methods. I think we tried all the popular ones and were not satisfied. We ended up with a custom linear model with 7 parameters, and we set these parameters by the whole product group. In the first session, as I remember, we spent half a day processing 50 features/requests and the resulting backlog was good enough, but it was also very close to my intuitive backlog.
It means this complicated process had no benefits and did not produce any significant insights.
Was I more confident about our roadmap after this session? Yes, for a day.
It was good for a product group alignment though, since we had conversations about problems and it helped to share the context between several people.
OK, let’s get back to RICE.
Why RICE is not good enough?
RICE is just a proxy for your intuition
Let’s be honest, we still use intuition when setting Reach, Impact, and Effort. There is a Confidence factor that we use to compensate for our intuition, but collecting real evidence is usually very hard, so from my experience, we tend to degrade and just put some average confidence into most features. It is better than nothing, but in reality, I see no real difference between RICE and gut feelings.
RICE is hard to align
My perception of Reach and your perception of Reach for a single feature will vary. If you have several product managers in your company, they will produce RICE scores that can’t be compared. My RICE scores are apples 🍎, your RICE scores are oranges 🍊.
We can try to solve this problem via “let’s estimate all features as a group”. Here you reach some consensus and even build some alignment, but it is very time-consuming. From my experience, this practice rarely sticks. Anyway, it is the best we can do.
RICE is biased
We can predict Reach for some features, but can’t for others. For example, performance improvements will reach ~100% of users, while some security improvements will reach a completely unknown number of users. So these features may be always deprioritized, and you will have to use some other backlog to not die from a hacker attack.
I will not even touch Kano, MoSCoW, or other methods here. They don’t provide any additional insights.
Prioritize based on facts
A few years ago I asked myself a very simple question: “Can we bring a scientific approach to prioritization and decision-making?“. To answer this question, let’s briefly dig into what a scientific approach is and how it relates to our problem. Here are the most important things:
- It is based on facts (real-world data). In our case, most facts live in product feedback (there are facts in a market as well, and for early-stage startups, most facts are from the market).
- It is objective. It means if you take two product managers and give them 10 features to prioritize, they will get exactly the same backlog sorted by priority.
What is a fact?
In our context, a fact is a piece of information about a product, augmented with some metadata. Let’s say, you have a call and a customer says “We have huge troubles with onboarding, few people get the product, but almost all new users don’t understand it and tend not to use it.” This is a fact. It lacks details, like why exactly this is happening, so you should go deeper and ask more questions, thus discovering more facts. But it is already useful. In a call, you can collect many facts about the product.
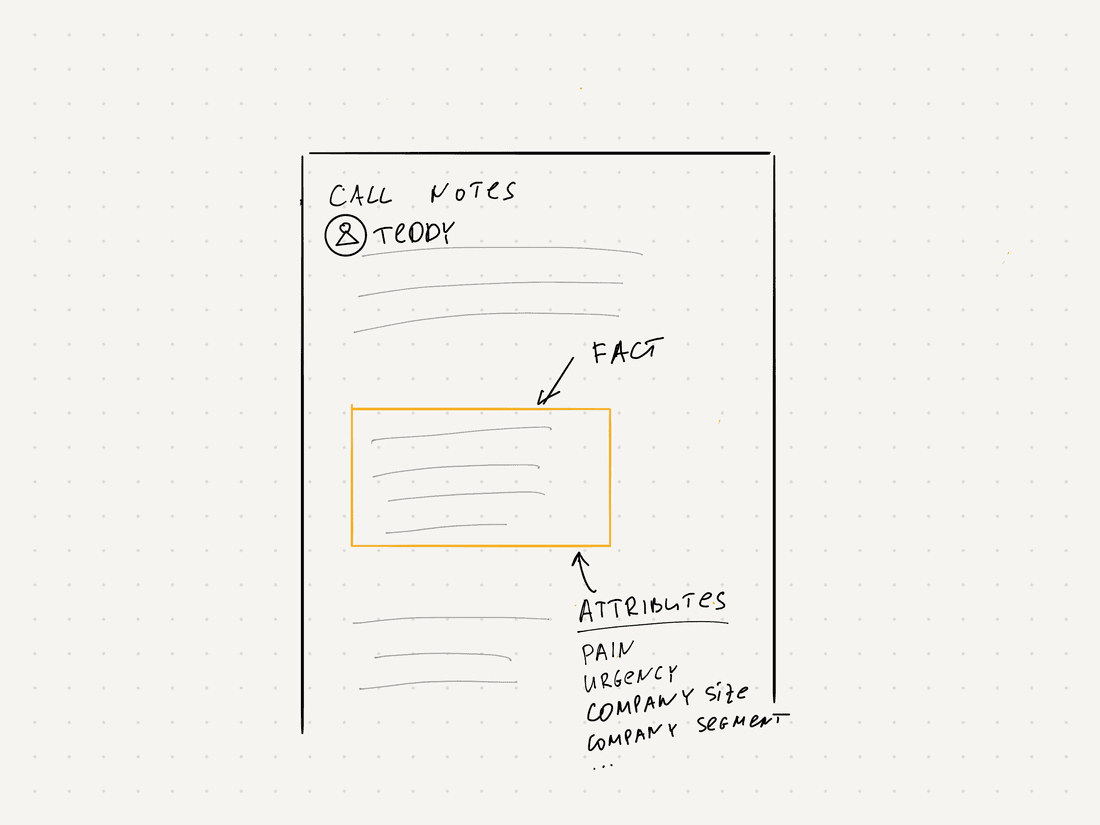
Examples of facts at a random B2B company
Let’s begin with an example before we generalize. We have a B2B company that develops a business intelligence platform, targeting companies with 500+ employees that engage in data-heavy, interconnected processes.
We’ve found that European companies are of greater interest to us, given their lower churn rates, and we’re currently not prepared to expand into the US. This company has identified 786 potential issues. The question is, what facts and signals should we use to determine what to build next?
- The amount and frequency of feedback (for instance, one issue was mentioned by 8 customers/leads, while another was mentioned by 76).
- The size of the account (feedback from a company with 50 employees is not as relevant as feedback from a company with 1000 employees).
- The region (feedback from a US company is less valuable than feedback from a German company).
- The level of pain (the severity of the problem varies from company to company; one might not find it a major issue, while another might refrain from purchasing because of it).
- The amount of data (feedback from an account with 50K records per month is less valuable than feedback from an account with 1M records per month).
Most of these factors are objective (although the level of pain is somewhat subjective, we can use a sentiment score, which should suffice). Now we can develop a prioritization framework that calculates a priority score based on these signals.
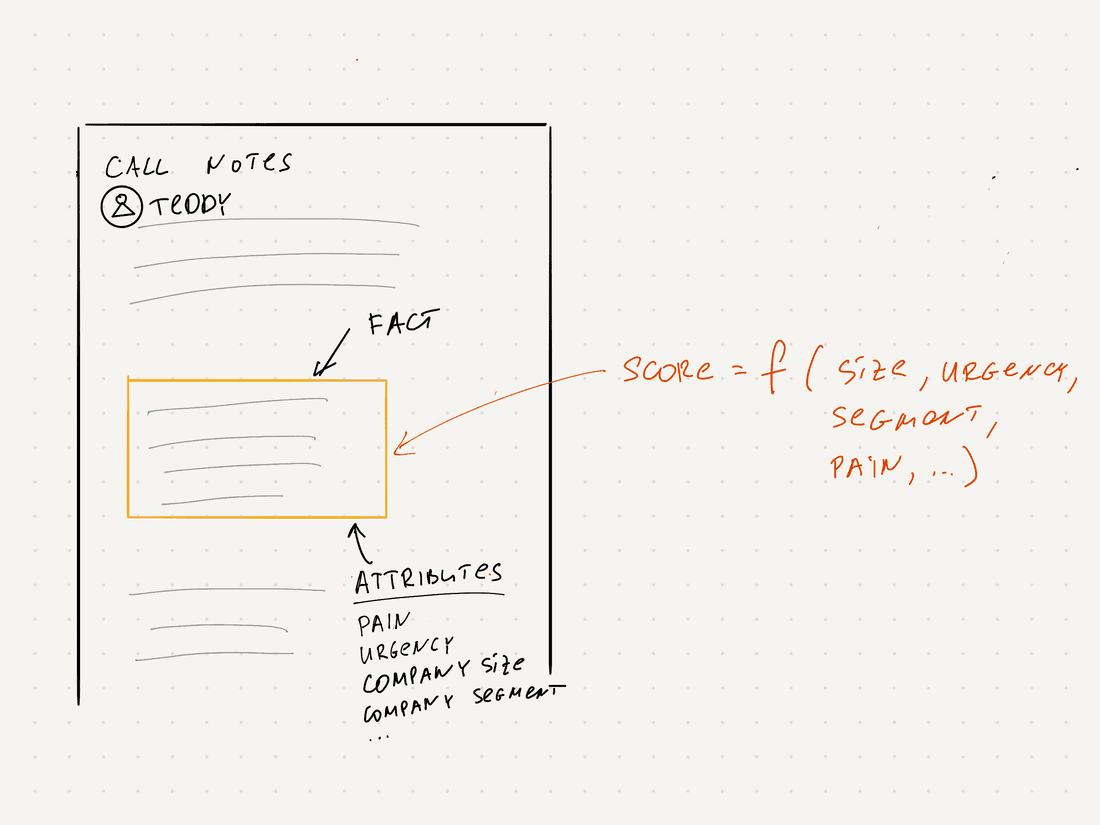
The facts-based prioritization process
Let’s try to generalize it now. Here is how to make it work and what we have to do:
- Collect all feedback from customers and interactions with leads (calls, chats, community forums, in-product feedback, surveys, etc).
- Process the feedback: find facts (highlights), and link these facts to the problems or features backlog.
- Connect feedback highlights to CRM (here we will get facts about account size, region, etc).
- Create a custom prioritization model for a backlog that considers all facts and signals that are important for a company at this very moment.
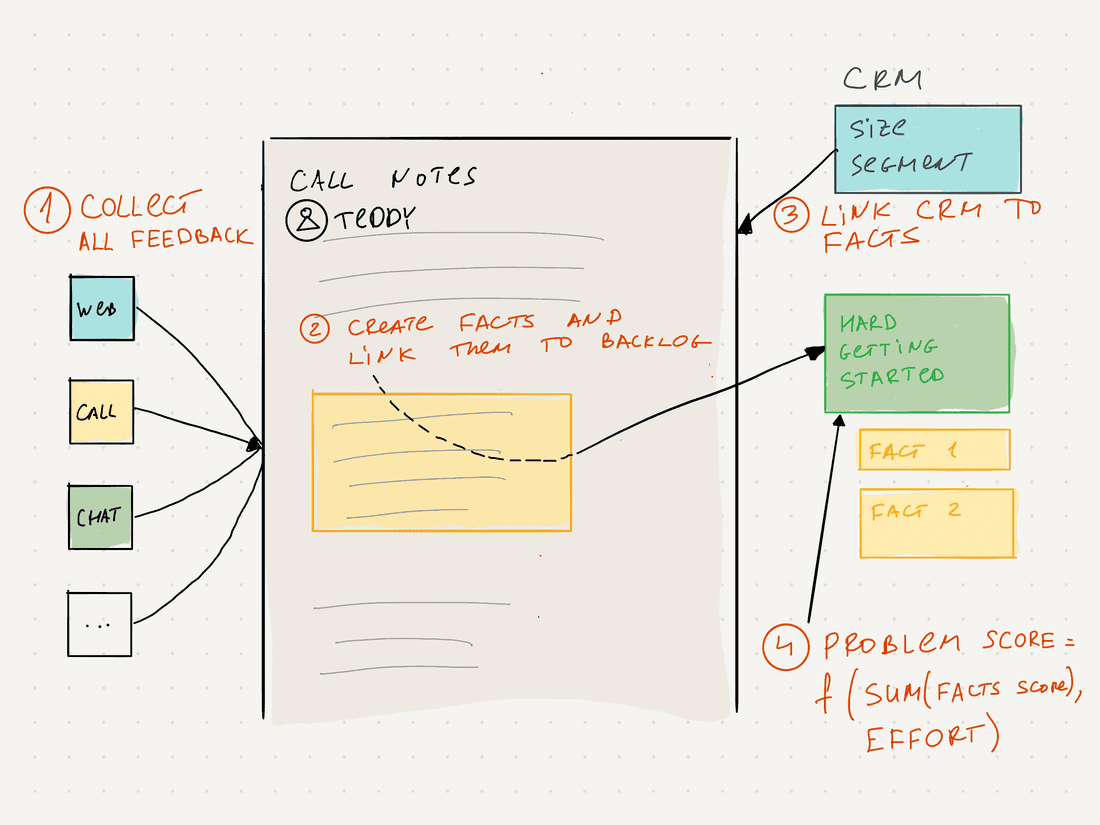
Now you can have a backlog sorted by a score that is based on quite objective data, and a backlog becomes trustworthy. The benefits are clear:
- Fewer wrong features will slip into development.
- Roadmapping decisions are easier to make, articulate, and defend.
- Reduced anxiety.
Tools
Can you build this process in some tool now? As far as I know, only Fibery can do it with good enough customizations to fit your process and specifics. In Fibery, you can collect all feedback from customers and interactions with leads (calls, Intercom chats, Slack communities, custom surveys, etc). Then you can process feedback, find facts (highlights), and link these facts to the backlog.
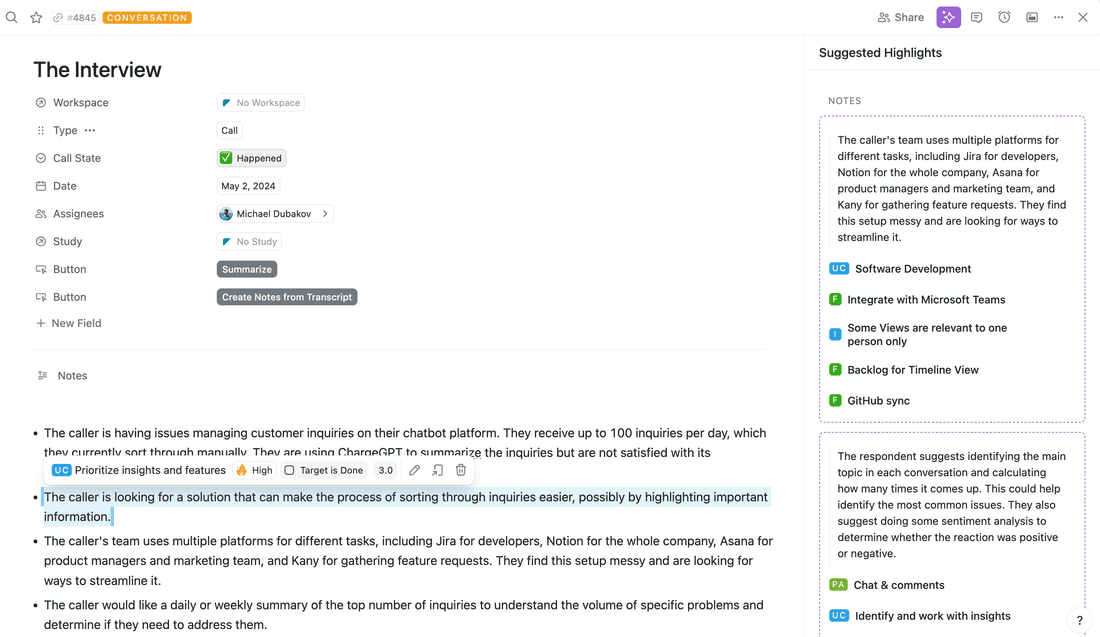
You can connect feedback highlights to CRM (Hubspot or Fibery) and, finally, create a custom prioritization model for backlog items. For example, in this backlog, the Highlights Score includes facts amount, account size, account segment, and fact’s pain level.
Conclusion
Traditional prioritization methods like RICE often rely on intuition and subjective assessments, making it difficult to align priorities and make informed decisions. However, a fact-based approach offers a more scientific and data-driven solution.
By collecting and analyzing feedback from customers, we can identify objective facts about the product’s pain points. These facts can be linked to the backlog and prioritized based on signals like feedback frequency, account size, region, and pain level. This approach ensures decisions are based on real data.
Not fully satisfied? Want more tips? Remember, we have a webinar just around the corner. Register for free here.
Psst... Wanna try Fibery? 👀
Infinitely flexible product discovery & development platform.