Augmenting Organizational Intelligence
- Productivity vs. Insights
- Brain ↔ Organization Analogy
- Information Chaos
- Structured and Unstructured Information
- How Knowledge Forms?
- Information Evolution
- Accumulate Information
- Mix Information
- Connect Information
- Visualize Information
- The promise: increase the probability of insights
- How to inject this tool into organizations?
- Summary
We’ve started Fibery more than 4 years ago. The main idea was to create a work management software that grows with a company and flexible enough to replace a couple of work management tools. The vision was deep and ambitious enough, to be honest. But learning never stops.
Suddenly we understood that we’re solving a quite interesting and complex problem, but not THE problem. Fibery 1.0 focuses on work management, but the real problem is knowledge management and new knowledge generation. So we have to go even deeper, we have to think about augmenting organizational intelligence.
Here is what Doug Engelbart wrote about human intelligence augmentation.
Increasing the capability of a man to approach a complex problem situation, to gain comprehension to suit his particular needs, and to derive solutions to problems. Increased capability in this respect is taken to mean a mixture of the following: more-rapid comprehension, better comprehension, the possibility of gaining a useful degree of comprehension in a situation that previously was too complex, speedier solutions, better solutions, and the possibility of finding solutions to problems that before seemed insolvable. — Doug Engelbart
We want to extend this reasoning to organizations. This paper is a conceptual framework that can be transformed into a tool.
🙇 DISCLAIMER: We deliberately ignore all social factors and focus on a tool. We deliberately ignore adoption challenges and processes, internal politics and lack of transparency, resistance to changes and inertia. Keep this in mind.
Productivity vs. Insights
Most existing tools focus on productivity and efficiency. They promise to make your organization more productive and more efficient. For example, Clickup even promises to “save one day every week”. Not sure what you will do with the free day, probably fill it with more work. What is productivity? What is efficiency? How to measure the productivity of knowledge workers? If you ask this question to any vendor, you will hardly get a good answer.
Most existing productivity tools work just like memory extension plus some collaboration. You put some data in, notify some people and find some data when required. It saves time, but is it the best what we can get?
We think the better metric is the quality and quantity of insights 🔮. The more insights a knowledge worker generates in a given timeframe, the more productive she is.
What is intelligence and what is insight?
👉 Insight is a piece of new knowledge. It can take many forms: a new question, a new answer to an existing question, a new theory, a new proof, a new experiment, a result of an existing experiment, etc. Here are some examples of insights:
- What should we focus on next in our product?
- It seems we have better traction in the new startups’ niche!
- What our competitors have in common?
- Hmm, do we have a new market opportunity here?
In a knowledge economy, we compete with knowledge, not force. Our productivity tools should become knowledge management tools as well — thus, making companies more intelligent.
👉 Let’s define intelligence as quantity and quality of insights. Indeed if we can experiment faster, answer questions faster and better, we have more chances to succeed.
Intelligence demands execution. That’s why the knowledge management and work management dichotomy is false, we have to unite these spaces. Our tools should not only manage work, but they should also increase insights probability for knowledge workers.
Brain ↔ Organization Analogy
So far we have a single model of intelligence — the human brain. We don’t know much about its structure and concepts. Still, we know something and can try to bring this analogy to organizational intelligence. There are several things we know about the brain:
- The brain accumulates information (facts, hypotheses, etc.)
- The brain mixes & connects information together, forming a knowledge network.
- The brain is the single storage of new knowledge in an organism (we don’t store facts and connections in kidneys or liver).
- The brain constantly explores various possibilities and forms new connections, thus generating new knowledge. Sometimes trivial, but sometimes genius.
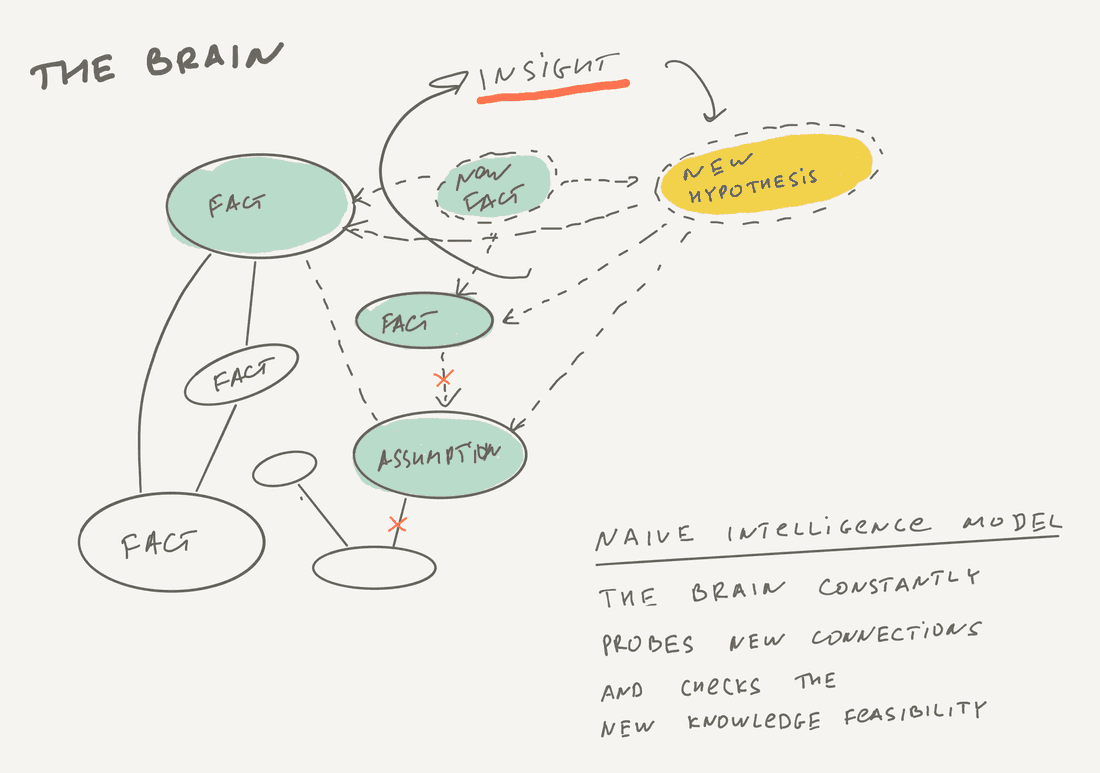
Let’s transfer this model to an intelligent organization (we all know that analogies are dangerous, but we also know that is how we invent new things):
- An organization accumulates information (facts, hypotheses, etc.)
- An organization connects information together, forming a knowledge network.
- An organization stores everything in a single place.
- An organization constantly explores various possibilities and forms new connections, thus generating new knowledge. Sometimes trivial, but sometimes genius.
It is easy to see that in any organization we have problems with 2 and 3, and problems with 4 as a result. All that reduces organization intelligence.
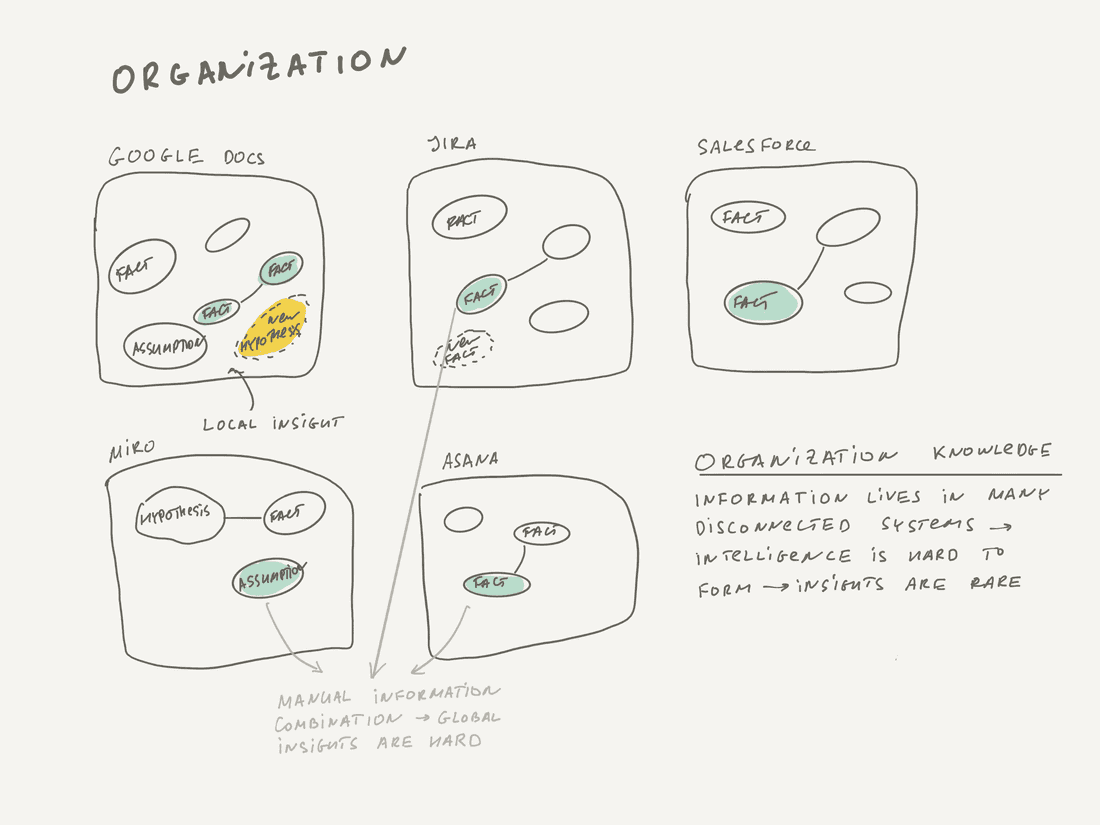
🚨 Organizations store information in different places: Notes, Spreadsheets, CRM, Project management tools, etc (dozens or hundreds of tools). It creates many walls and barriers, information retrieval becomes much harder.
🚨 Organizations connect existing information poorly. Usually, this is done manually by human beings via Dashboards, PowerPoint presentations, and analytical memos. You have to dig into many information sources, connect them in your head and produce a presentation or memo.
The conceptual solution looks trivial now:
🌶 We should have a tool that accumulates information in a single place and has instruments to collaboratively create, mix, connect, visualize and retrieve information.
Every word in this definition is important and unfolds into a serious list of properties and features. We will explore the main properties in greater detail below. Here is the summary so far:
- It should be possible to store free-form unstructured information like any text and media and put a structure on top when required (define ontological data model). It should be possible to accumulate information from many existing tools.
- The information creation process should be collaborative by nature.
- It should be possible to collaboratively connect the information in all possible ways (bi-directional links, relations, transclusions, etc).
- It should be possible to visualize information in all possible ways.
- It should be possible to navigate information using search, category browsing, and hyperlinks navigation.
When we’ll have such a tool, it will increase organization intelligence by increasing insights probability for knowledge workers. How? There is no quick answer to this question. You have to read to the end to get the answer, sorry.
Or Make a Pause and Try Fibery Right Now
Btw it adapts to your team and grows with it.
The tool is not everything, there should be methodology and discipline in place. But the tool will help to fight information chaos inside an organization.
Information Chaos
Internet in 1997 is a good analogy about what is happening now in organizations. There was no unified mechanism to find information on the internet, we had to browse through Yahoo! catalog or bookmark websites to not lose them again. Information was hard to discover and hard to connect. Let’s say you were writing an article about the flu vaccine. Where to find information? Go to specialized medical catalogs? Try Yahoo? Ask some doctor in a forum? You had a hard time finding interesting info and putting correct hyperlinks to other sources.
Everything changed with Google. Now we discover information in a unified way (mostly). Google is the default way to find new things and as a result, more information pieces are connected together. Well, it is not as rich as Ted Nelson imagined, but at least it’s a huge step forward.
Let’s define three levels: Human, Organization, World. Every human possesses some volume of knowledge that usually expands through the lifetime. The same concept is true for organizations and the whole world. Do we have a unified mechanism to store and share the accumulated knowledge? The answer is no.
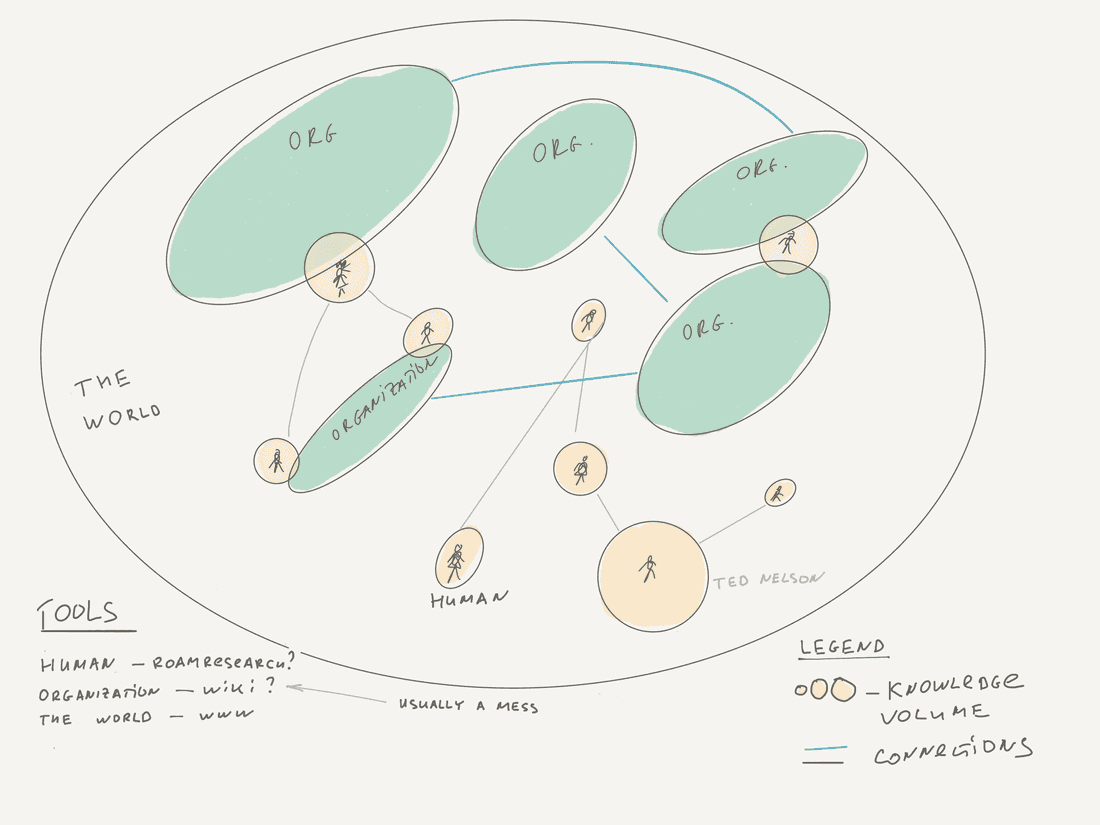
Human-level
Most humans that produce new knowledge store and share it somewhere. Why it’s beneficial on a personal level? It’s like a brain extension where we can dump information and connect it eventually, thus discovering novelty. We can re-read some topics and suddenly remember important things that can shine with new colors in our new current context. However, tooling is quite poor even at this level.
Few highly-disciplined individuals use advanced systems like Zettelkasten. Most use notes taking software (Evernote, Notion, Apple Notes). Some people publish books and articles. However, most knowledge is dispersed. There is no easy way for any human to accumulate connected knowledge and share it with the world. Roam Research is a recent promising attempt to solve this problem.
Organization level
Things are even worse on an organizational level. Information handling inside companies is just like the Internet in 1997. You have many disconnected tools and have to browse or search inside these tools to find what you need. Connectivity is also poor, there are no rich connections between Google Docs, Jira, Trello, Salesforce, or other specific software for specific processes. All you have are basic hyperlinks, but there are also access issues, since not so many employees have access to CRM, for example. There is no universal mechanism to discover and connect information. All that seriously impedes intelligence formation in an organization.
The real problem is that 🚨 knowledge management and work management are separate things in an organization, and there are different tools for these things. Indeed the current status quo is a set of specialized tools to handle structured information (Asana, Jira, Salesforce, Intercom) and tools to handle unstructured information (Google Docs, Confluence, Miro, Slack).
The Knowledge Organization: “In a creative organization, work management is knowledge management. The architecture you choose shapes the way knowledge is captured, discovered, and shared.”
This is just wrong since the knowledge and work management dichotomy does not exist in reality. It’s an artificial construct.
Another serious problem is a collaboration between many people. Imagine, I created some idea and put it into Asana. How other people can discover it? How do they know that the idea lives in Asana? How to connect it to some feedback aggregated in a Google Doc? How to compare it with other ideas that live in other places? Every single tool has its own collaboration mechanisms: notifications, search, categorization, access. Collaboration is not unified, and this lack of unification also seriously impedes intelligence formation in an organization.
No existing tool solves this problem. We have a big black void here.
Human/Organization vs. The World
If you are curious about history, check Hypertext tools from the 80s article.
It’s somewhat strange that we have some good enough knowledge organization solutions for the whole world (WWW), but don’t have good solutions on more basic levels.
Indeed it is relatively easy to create a tool that simplifies knowledge management for a human. It is harder to create a similar solution for the organization. But it looks almost impossible to do that for the whole world. Yet that’s what happened…
Now we try to penetrate the problem of knowledge management and create the new knowledge management system concept. Let’s start with the first principles and try to choose the right level of abstractions.
Structured and Unstructured Information
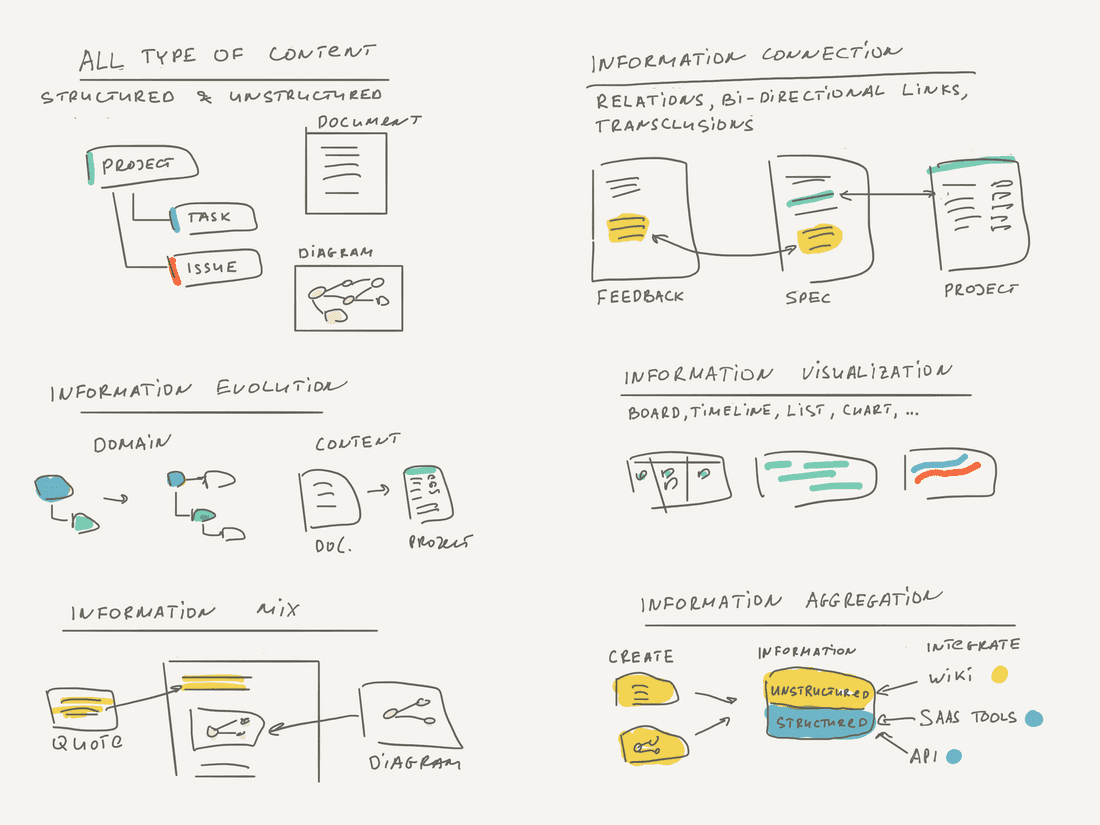
First, let’s talk about information types. People don’t think about structured and unstructured information dichotomy often. Here are a few examples to guide you.
Sometimes this is called semi-structured information, but we’ll use the unstructured term.
👉 Unstructured information: note, chat, text paragraph, document, diagram, image. Basically, unstructured information has poor metadata. We don’t know what is a note about till we read it. We don’t know what is an image about till we see it.
👉 Structured information: feature, animal, construction plan, protein formula, succulent image. Structured information always has rich metadata and forms a group/category/ontology.
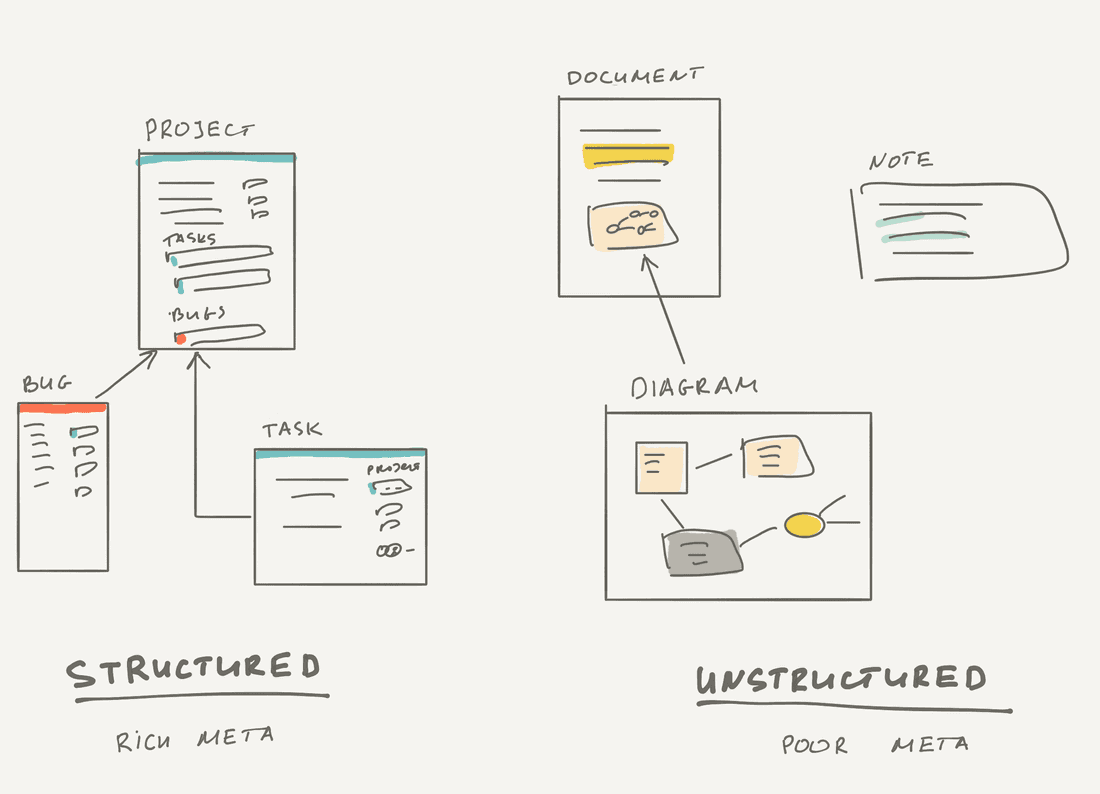
Interestingly, almost all existing software tools don’t support both, but focus on one type: Google Docs, Confluence, Miro work with unstructured information; Jira, Asana, Salesforce work with structured information. There are some exceptions, like Notion and Coda, they work with both to some degree, but I’d say they are closer to the unstructured world so far.
Our tool should support both types of information. Why? It just resembles how the brain works.
We should not impose regularity where it does not exist — Ted Nelson
Currently, you need at least 2-3 tools to work it out. For example, you may use Jira for structured information, Confluence for documents, and Miro for diagrams. The downside of this approach is 🚨 poor connectivity. When all kind of content is in a single place, you have the power of hyperlinks and fast knowledge navigation at your disposal. When everything lives in different tools, you have walls to penetrate.
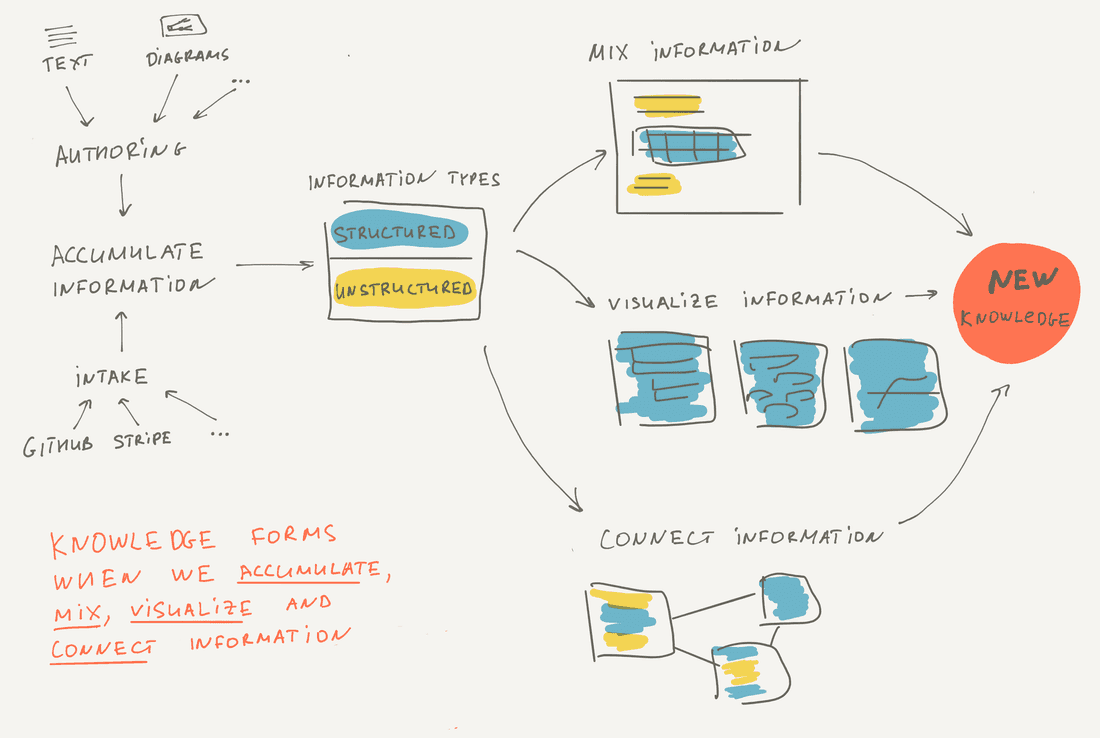
How Knowledge Forms?
The problem is that our brain does everything by itself. All we need is to accumulate facts by reading books and articles, watching videos, and thinking. We can’t control information connections directly, we can mix and visualize information using our thoughts somehow, but we don’t really know how all this works. In any external system, everything is explicit. You have to put the facts in, you have to create useful visualizations, you have to add connections and you have to mix information manually. Any external system for knowledge management will always be slower and harder to use than our brains.
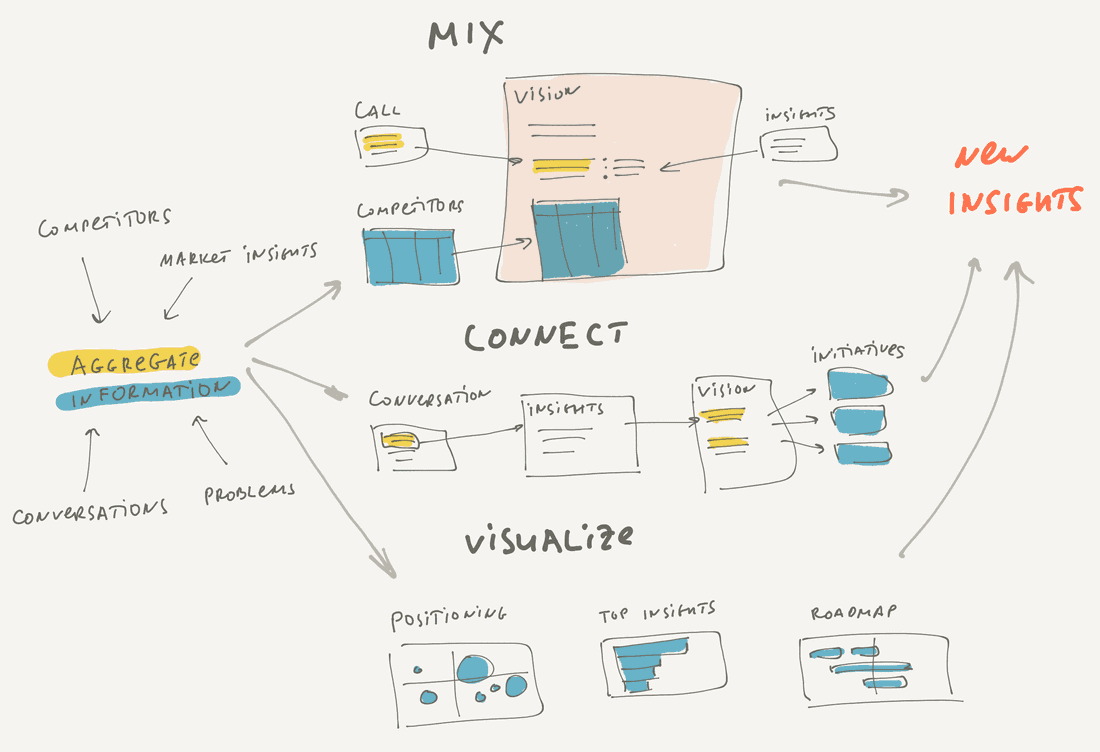
Knowledge forms when we accumulate, mix, connect and visualize information. Indeed we should accumulate facts to generate any insight, this is just a preliminary condition. But what’s next? How we form new knowledge? There are several ways.
First, we can mix structured and unstructured information together in a single view and it can give us new thoughts. Let’s say we create a document where we write some text, include some diagrams, include some charts, etc. For example, we create a feature specification. We write a brief problem description, include several customers’ quotes, include existing solutions from some ideas, add a high-level diagram, include a list of tasks that should be done to complete the feature, include some bugs that will be resolved when this feature will be implemented. Note that we mixed existing information and added something new. This information mix forms new knowledge and potentially can help to generate insights. For example, looking at this mix you can spot a gap between customers’ problems and the solution and get back to specific customers to fetch more details.
Then, we can connect information together using various kinds of links. These connections can lead to new knowledge. For example, you connect all incoming customers’ feedback to Insights. With time it helps to understand what Insights are more important.
Finally, we can visualize structured information using List, Table, Timeline, Calendar, Board, or Chart views. That is how we get the most value from connections since we can view the same information from different angles and play with it. For example, you create a list of features sorted by score (which is calculated of all connected feedback) and discover what feature is the most important now.
Most likely we will get a synergetic effect if all three ways of knowledge formation exist in a single tool. Indeed if you can mix, visualize and connect structured and unstructured information, you have all you need to produce new knowledge and insights.
Information Evolution
Information is not static. It changes and evolves. Interestingly, most existing tools just ignore information evolution. Let’s check how information can evolve from a structured and unstructured perspective.
Unstructured → Structured evolution
Unstructured information is great to capture things fast. We often don’t know how to categorize new information, it may be just a random fact. However, later we might discover that there is a category for that piece. For example, you see the collagen protein structure for the first time. You are not aware of proteins at all and don’t know what common properties they have (carbon atoms). So it may be just a random fact for you, but then you learn about proteins and suddenly this fact becomes a piece of structured information with more meta: 3d-folding pattern, gene location, length, etc. Now you can compare proteins, group them, find similarities and differences.
Similarly, in an organization, you might create a call transcript document with customer feedback. Initially, it’s just a text, but then you may transform or link some parts of the text to insights, features, bugs, and competitors.
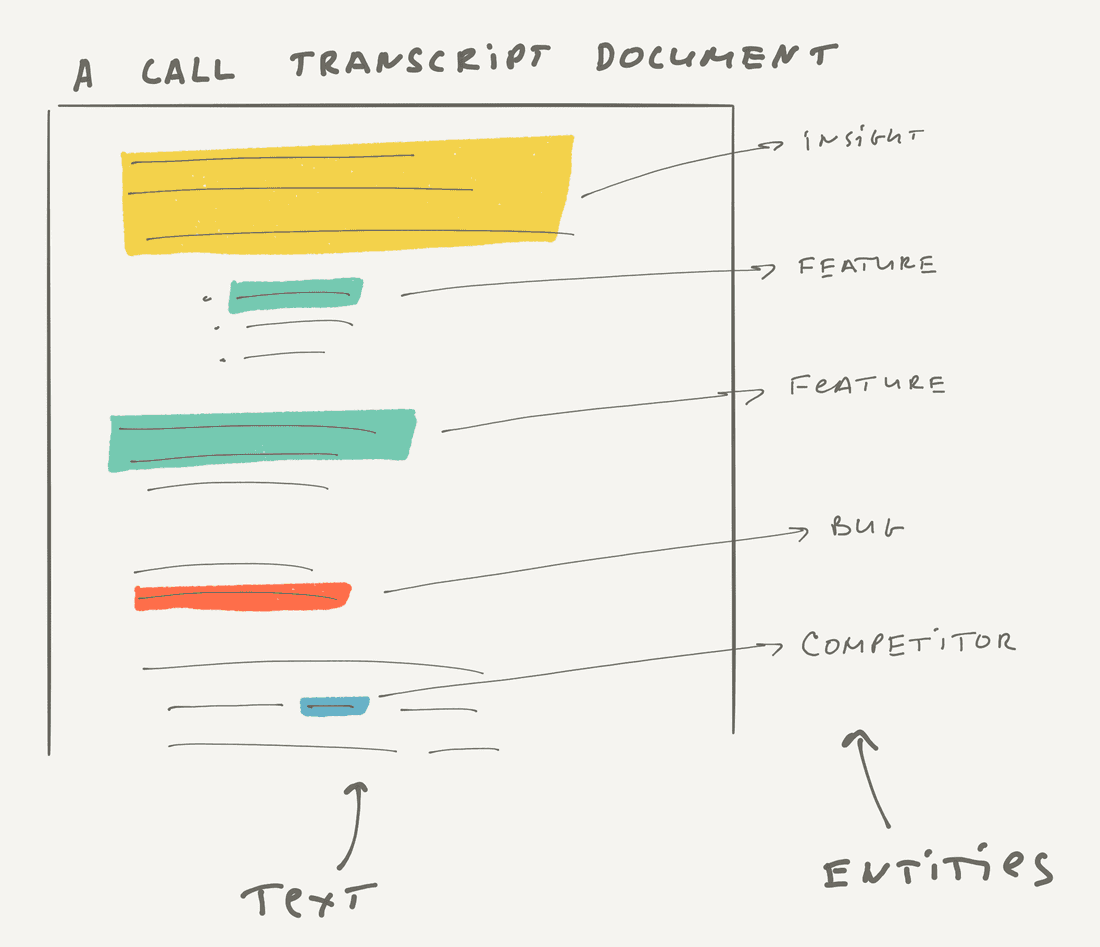
Another example is near real-time information flows: chat messages, comments, etc. This is unstructured information and sometimes we want to evolve it into structured, like create an Issue from a message, create a list of Tasks from a comment.
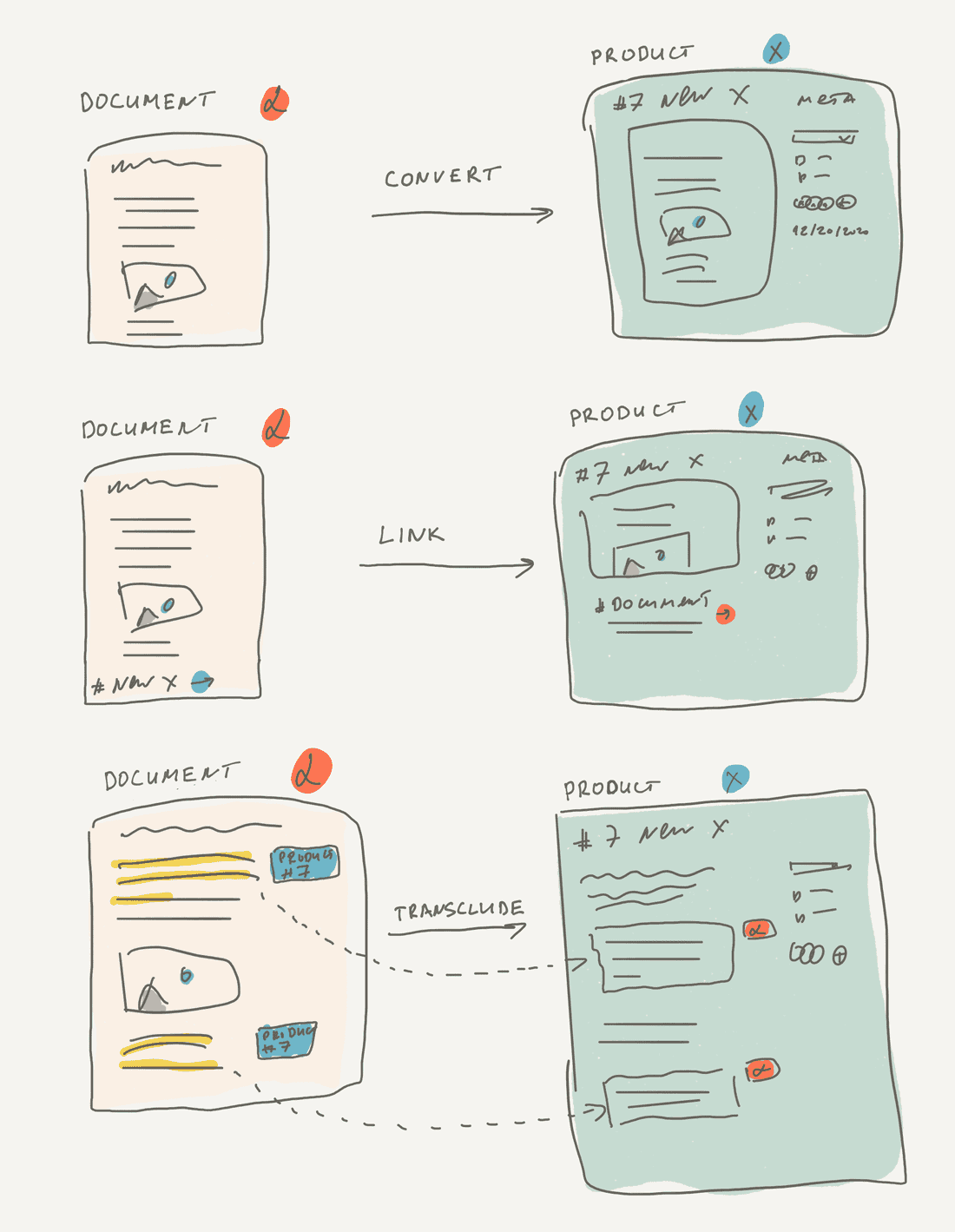
This evolution of information from Unstructured → Structured is essential. It’s just impossible to do in most existing tools and it restricts knowledge evolution. You may create new Structured information, but you’ll lose important context, history data, and access levels.
There are several ways to support this evolution.
- Convert Unstructured information into Structured, for example, a Document becomes a Product.
- Create a new Product and link the original Document to it. It’s important to have an automatic back-link from the Document to the Product as well.
- Transclude several parts of the Document into the Product (we’ll explain transclusions later).
Structured → Structured evolution
This evolution is slightly less important since structured things change less often.
Another thing is Structured A → Structured B evolution. We may change the category for any fact. Let’s say, you thought that a tomato 🍅 is a vegetable, but in fact, it’s a fruit. Now you know one more useless fact and have to change the category of a tomato in your memory.
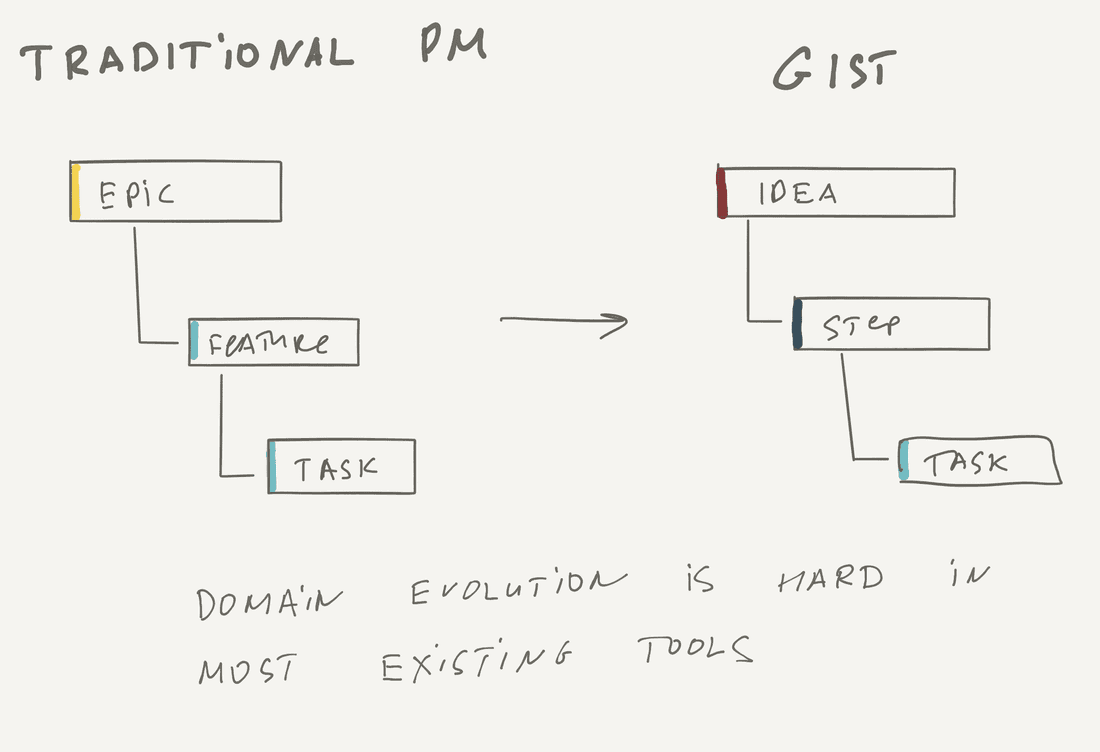
Another primitive example is converting Bug into a Feature. Indeed, it may appear that what the customer reported is not a simple bug, but a large missing functionality in a product.
A more complex example is the whole domain evolution. For example, you want to switch from traditional product management process to GIST Planning.
Now let’s get back to knowledge formation and dig into specific areas.
Accumulate Information
We have to accumulate information to produce new knowledge. There are just two ways to accumulate information for an organization:
- Authoring. You create information in a tool manually. For example, write a document, draw a diagram, add a task.
- Integration & Import. You can fetch data from external tools, like fetch all chats from Intercom, all tickets from Zendesk, and all transactions from Stripe. It’s also possible to fetch unstructured information from Notion, Confluence, Miro, and other similar tools.
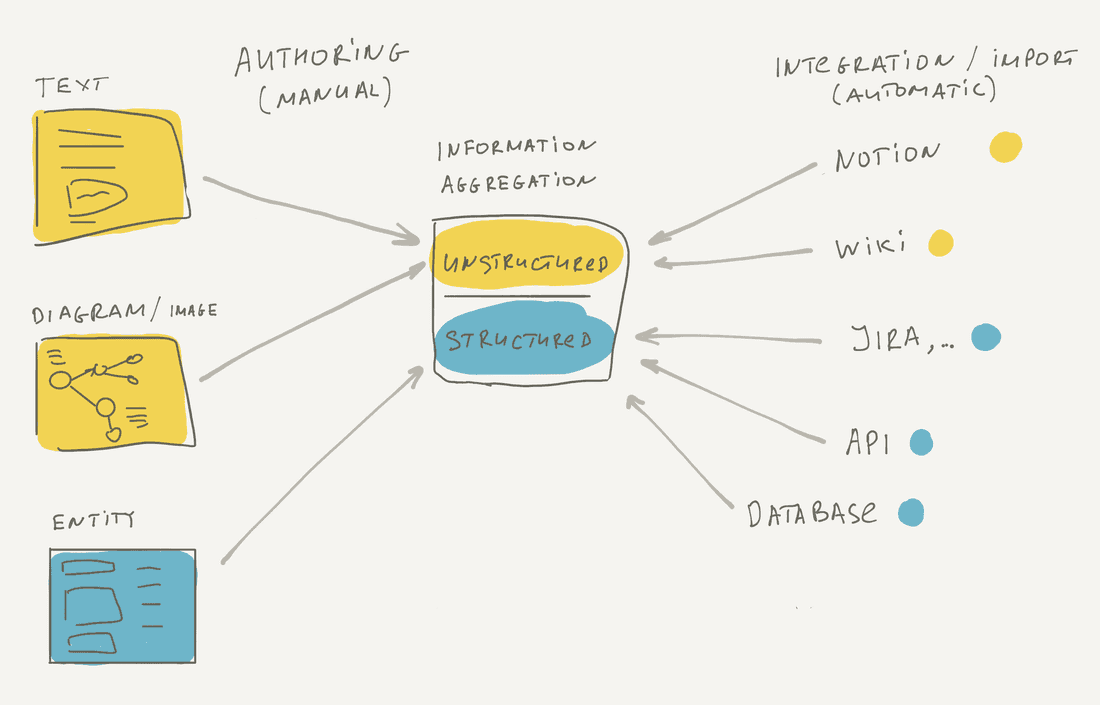
Our ultimate goal is to accumulate all important facts about an organization in a single tool. It means the tool should have a sophisticated text editor and a drawing/diagramming tool. It also means the tool should fetch data from thousands of existing data storage systems (databases, SaaS tools, files, documents).
Now let’s dig into knowledge generation.
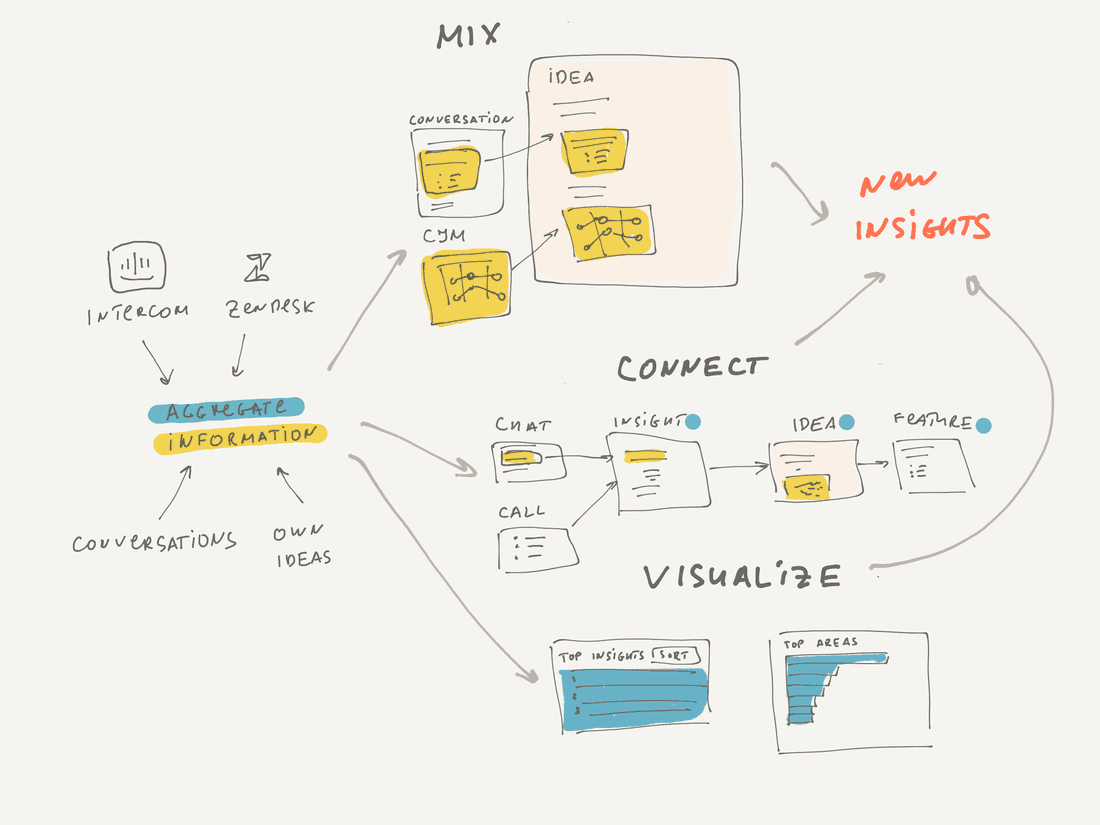
Mix Information
Knowledge is a mix of structured and unstructured information. It means we want to combine structured and unstructured information freely, without restrictions, thus producing new knowledge.
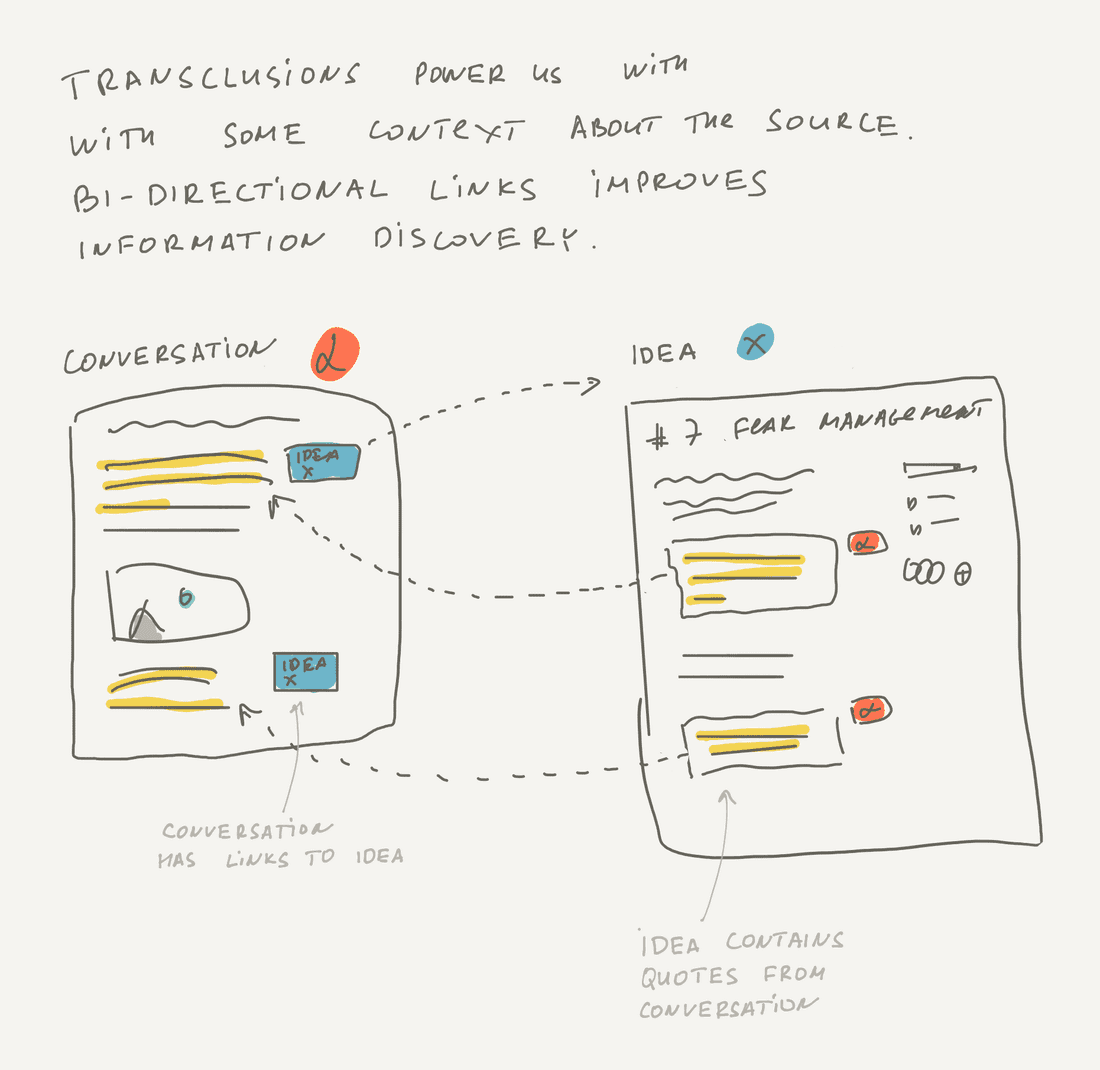
For example, I work on the “Fear Management” Idea and add a text with a problem definition. Then I want to support it with existing quotes from customers, so I find some conversations and transclude the quotes into the idea. Then I want to add a list of top requests related to “Fear management”, so I include a new block that shows a Table View with all relevant requests sorted by score.
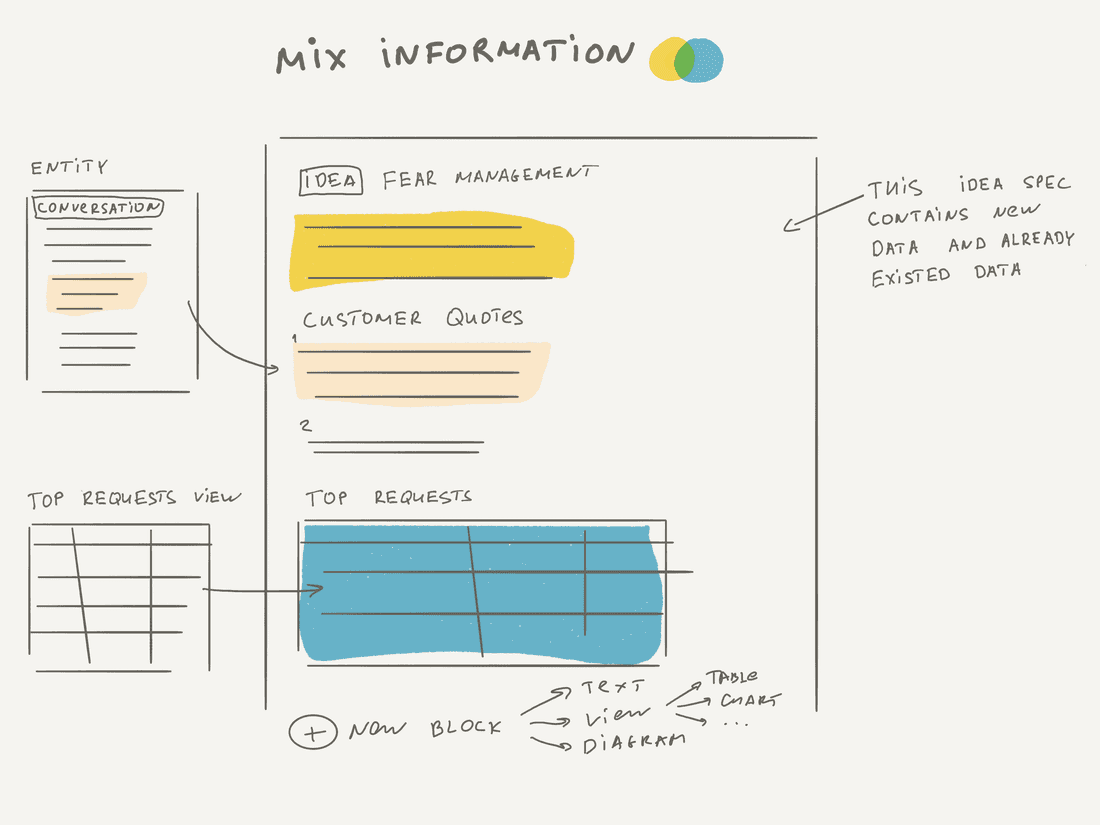
Notion and Coda can mix structured and unstructured information, but with some limitations. Still, if you are familiar with one of these tools, you should have a good mental model.
Note that most of the content on the image above already existed, we just mixed it in a new way. This mix forms a new narrative, but all information pieces are easily referable if you need to jump into them and learn the context better. You can navigate back to the original conversations and read them all or see what kind of customers requested that. Or you can navigate to the Top Requests table and modify it to include more information if needed.
Let’s take another example. Imagine you write a product vision document. You add some intro, define a problem, include a diagram that shows a structure of the problem domain. This diagram lives right here and can be modified right here, no external tools are required. Then you add several sentenced about competitors and included a List of all Competitors.
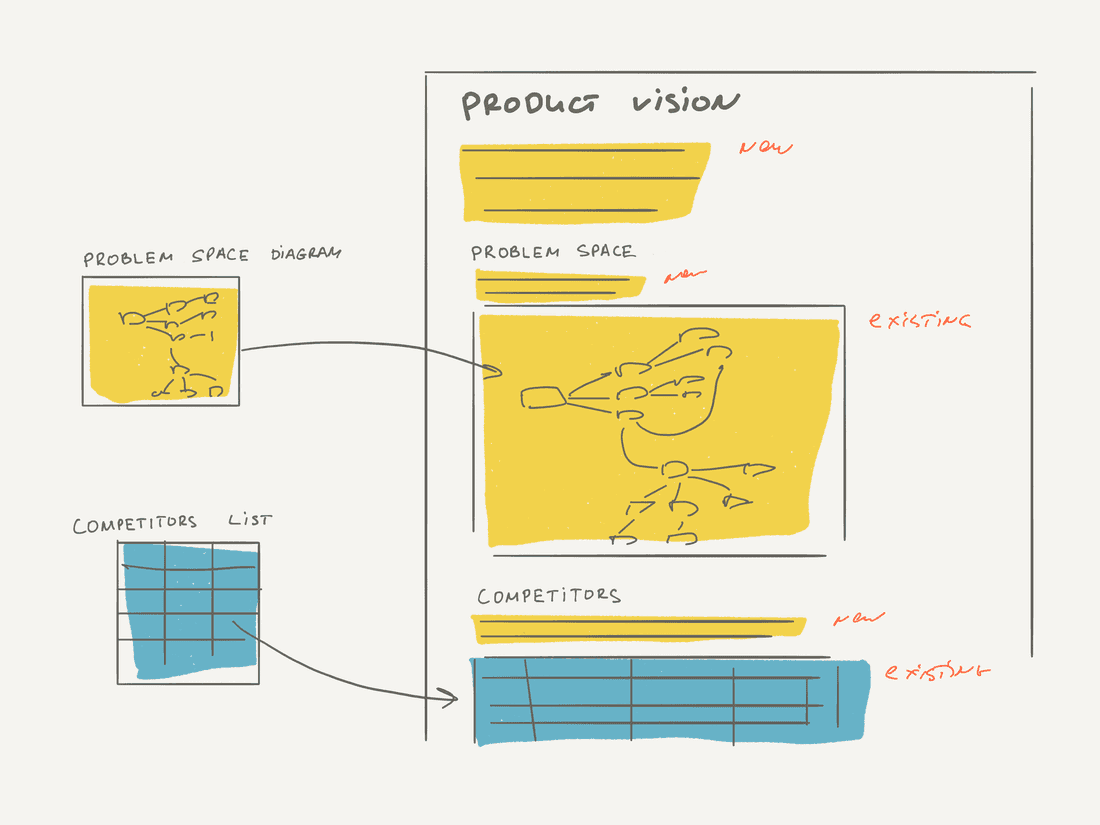
This is just another example where we can mix structured and unstructured information, but we also mix existing and new information. Essentially we augment our new text narrative with useful information blocks that already existed in our tool.
Connect Information
Intertwingularity is not generally acknowledged - people keep pretending they can make things deeply hierarchical, categorizable and sequential when they can’t. Everything is deeply intertwingled. — Ted Nelson
💡 Our tool should suggest possible connections between things. It can analyze the information and show potential connections based on text, images and metadata. It can give more weight to the information with many links. It can always include 1-2 random potential connections into this block to add some novelty. If the tool can build strong semantic constructs from the information, it can rely on matching algorithms that use “meaning” to link things.
Information linking is the core of brain intelligence. Our brain constantly generates new links, make some links stronger and few links weaker. It’s mainly about growth, not elimination (but forgetting is still there for some reason, so we might assume it’s important for intelligence). This process is beyond our consciousness most of the time. Night dreams are a good way to feel what our brain does, some dreams are super strange. But how to invent new things if you do not probe new connections?
In an organization we want to connect new facts as flexibly and as easily as possible. We want to connect new Issues to existing Ideas, some parts of the new Conversation to existing Ideas, some new documents to a project, etc. We want to create unified hypertext media in an organization. When we add and maintain connections, information discoverability improves enormously (imagine Wikipedia without hyperlinks…).
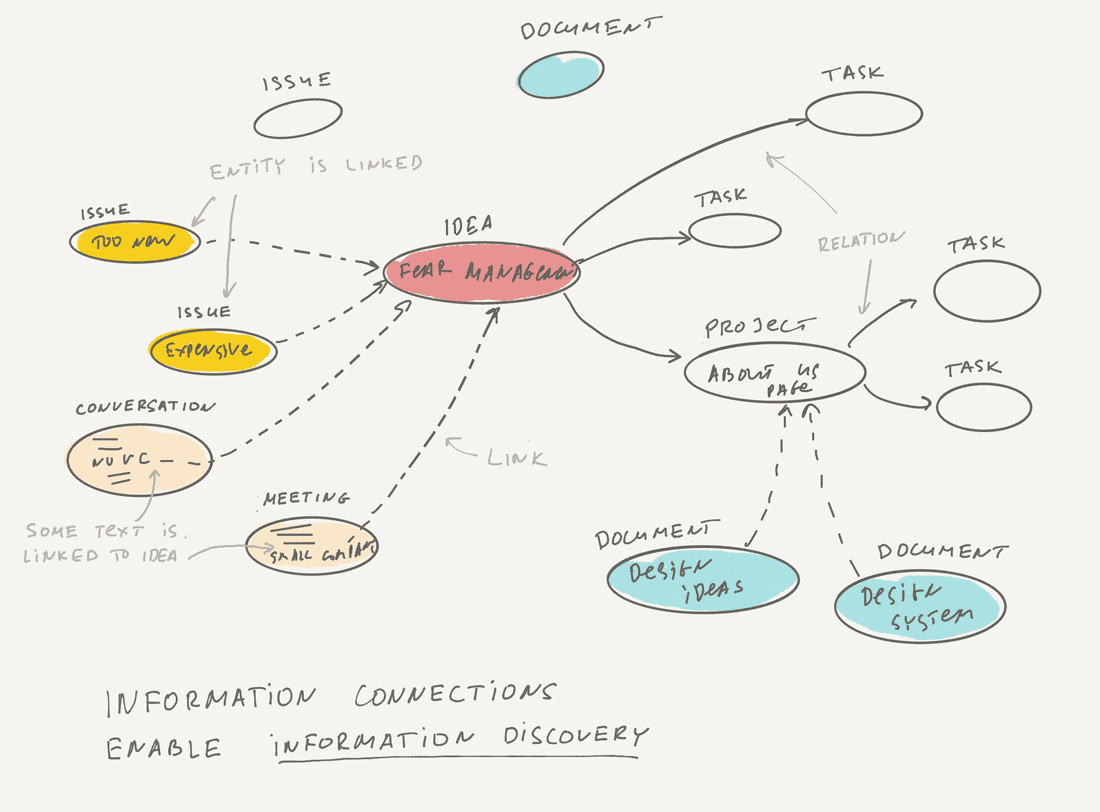
🌶 Links should be the first-class citizens in our tool.
There are several types of links, let’s briefly review them.
Uni- and Bi-directional Links
There are two types of links: uni-directional and bi-directional. You are familiar with uni-directional links from the web. Indeed all links in web pages are uni-directional and the target page knows nothing about the source.
These links are useful in simple cases, but they don’t form a context. Let’s say, you have 20 requests from customers that all link to the “Make you app faster” Issue. Looking at this issue you have no idea that many people are requesting it and what they say (maybe most of them used strong language).
On the other hand, bi-directional links are visible from both ends, and looking into this Issue you will know that it was linked to 20 requests and complaints were hot indeed. Bi-directional links are much more powerful.
The World Wide Web is precisely what we were trying to PREVENT. We long ago foresaw the problems of one-way links, links that break (no guaranteed long-term publishing), no way to publish comments, no version management, no rights management. — Ted Nelson
There are at least several ways to represent bi-directional links. The simplest way is to just have a list of incoming links, the more complex way is to include part of the source information (and that is something called transclusion). We are experiencing a Renaissance of bi-directional links, initiated by Roam Research. Now many tools are taking this idea seriously (finally).
We Do Have Bi-directional Links in Fibery, of Course
Btw it adapts to your team and grows with it.
Transclusions
Transclusion as a concept is not familiar to most people. However, poor mans’ transclusions are everywhere. When you embed a video from Youtube into a document or embed a Figma frame into a document — you use transclusion. Transclusions allow us to include one existing information piece into another, thus reducing information duplication and forming information trails more easily than usual links, since they provide more context.
Let’s say, you can just add a link to a diagram, but you have no clue what you will see till you click the link. When you transclude a diagram, you just see it right here without clicks. Note that the diagram exists elsewhere.
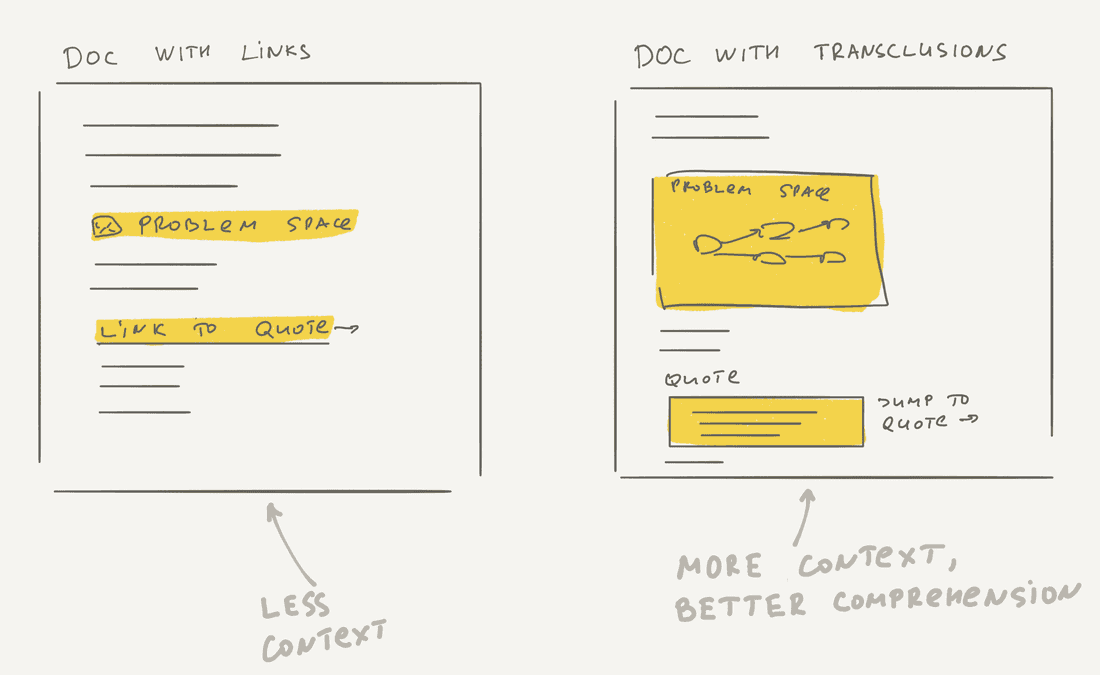
When you enhance transclusions with bi-directional links, you have a very powerful tool for information management. For example, you can transclude a single quote from Conversation into Idea without copy-pasting text, and have a back-reference to the Conversation from Idea. Imagine your teammate is reading your idea and just want to check the whole Conversation to learn more about the problem, now she can easily discover this Conversation and jump into it with a single click.
Relations & Hierarchies
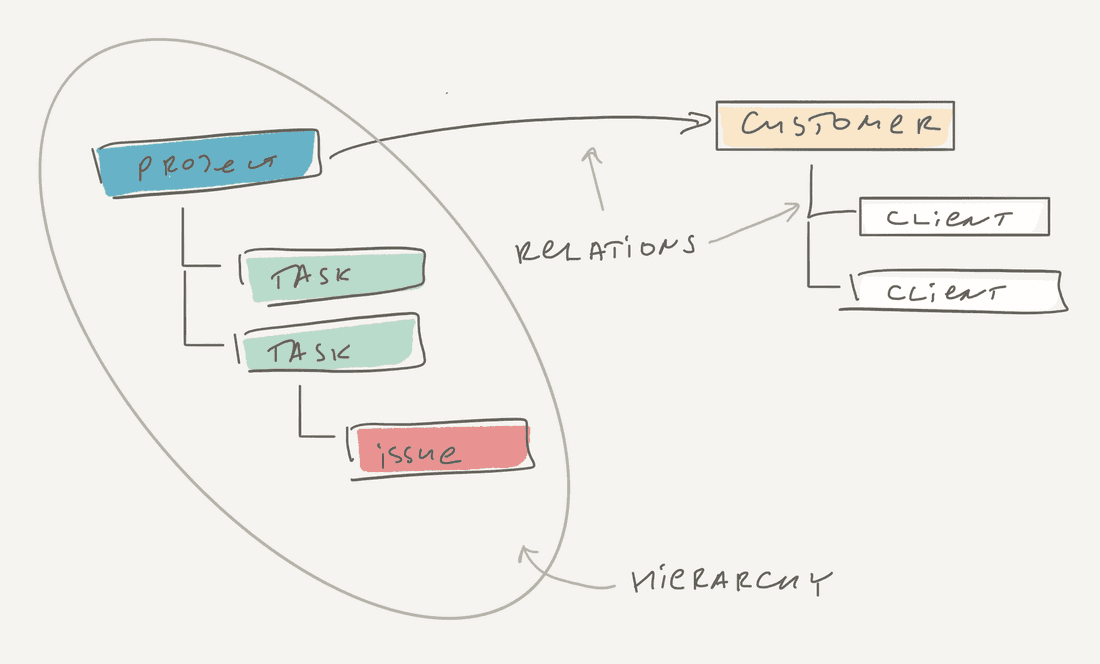
Structured ↔ Structured information has a unique link type: Relation. The main difference between the usual link is that relation is pre-defined. For example, you have Task and Project objects, and every Task has a relation to a Project. The relation might be blank, but it does exist in meta and you can always set it.
If you are familiar with relational databases, this is exactly that. Every table represents structured information and you can set relations between tables.
Almost always such relations as bi-directional, indeed you want to know what Project a Task has, or what Tasks are inside a Project.
With Relations you can build Hierarchies, they are very common in a structured information domain.
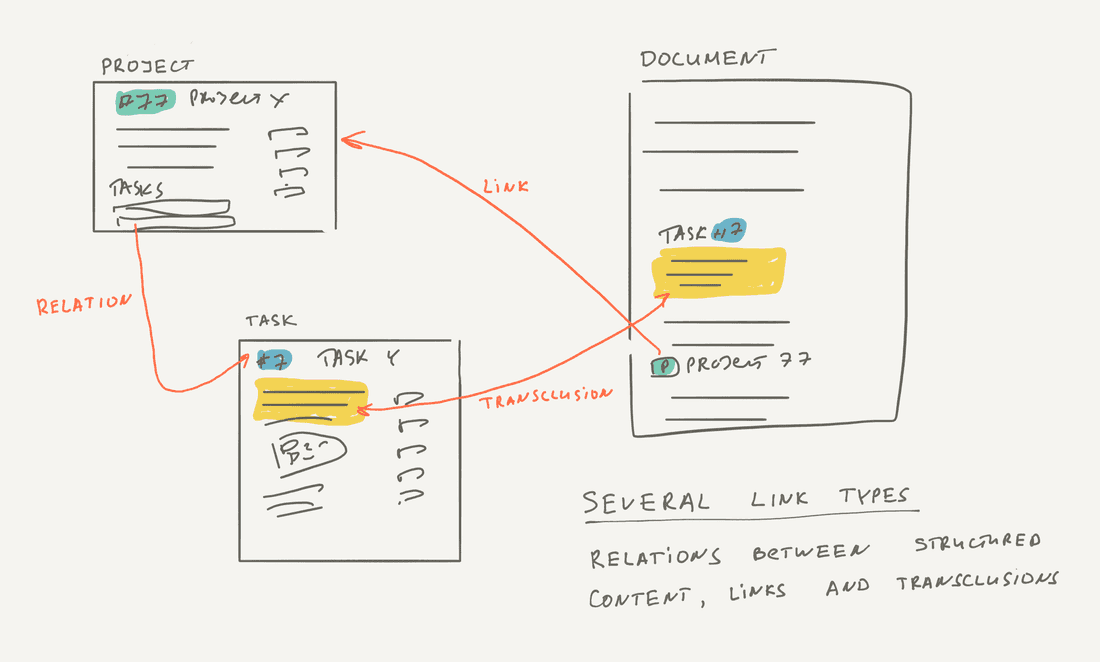
Here is the diagram with all types of links. As you see, it’s much more complex than basic uni-directional links in WWW. However, we need them all to generate knowledge on an organizational level.
Visualize Information
It’s hard to visualize Unstructured information since there are few properties that you can rely on. One solution is a canvas where you can put images, text, diagrams, and other things. Miro does this well. Another solution is a flexible document with images and transclusions (like in Notion). Simple web page is yet another way to capture unstructured information.
🔁 It’s interesting that vendors re-implement many of these Views in thousands of apps, what a waste of resources…
Structured information can be visualized in many ways. It’s really important to have freedom of information visualization since these tools help us extract meaningful information from the accumulated knowledge.
It’s possible to unify visual data representation with just 7 Views: Hierarchical List, Board, Timeline, Calendar, Table, Chart/Report and Network.
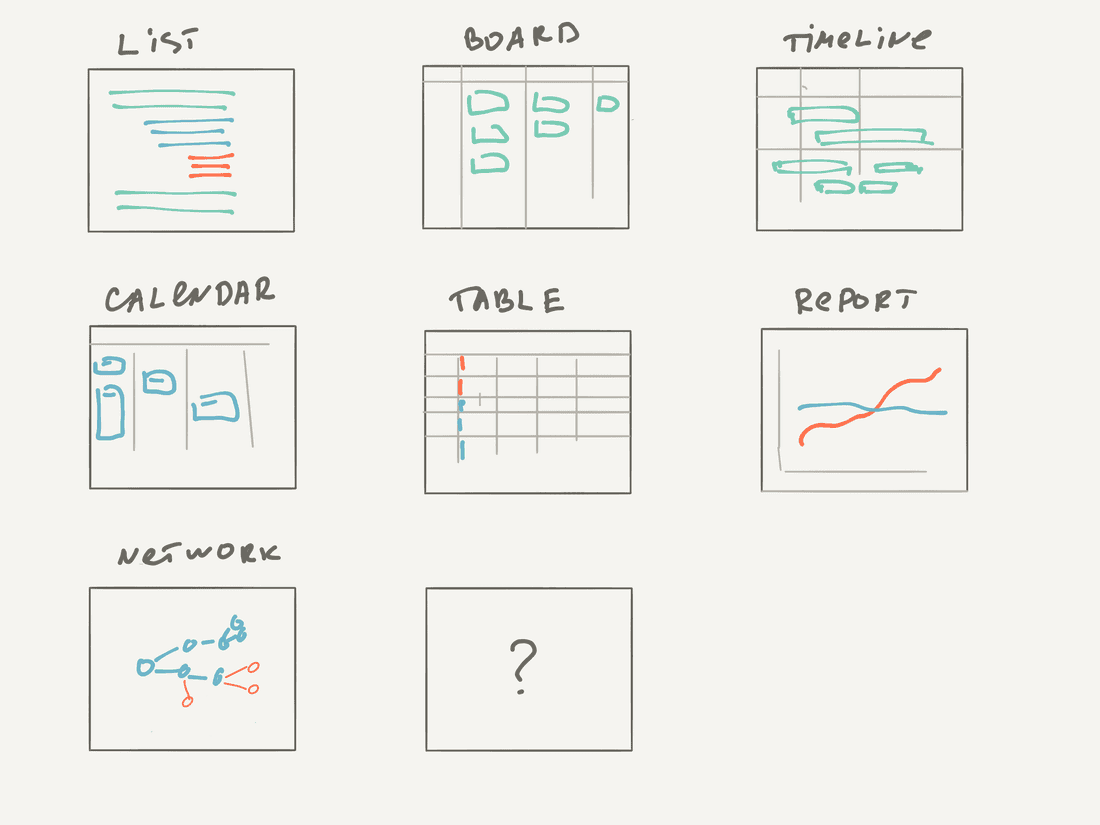
All these Views should be feature-rich and enable data manipulation functions: sort, filter, color, group. All these Views should be interactive and enable direct data manipulation, like add a new entity, change fields, do batch actions. Otherwise, it will be hard to extract new information from the data.
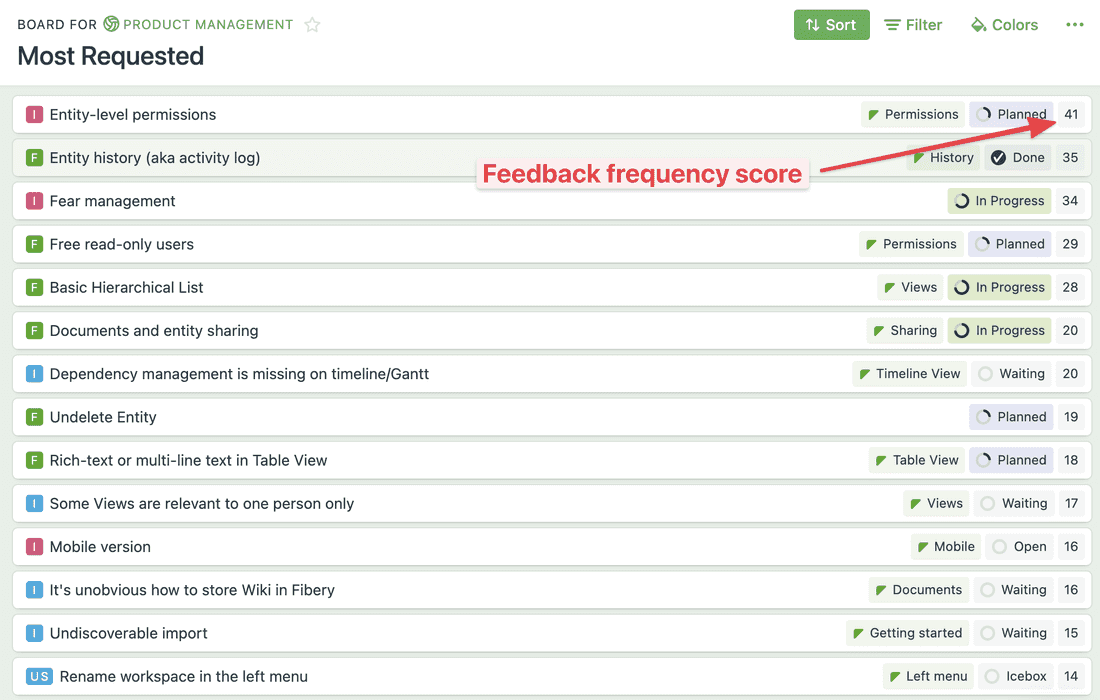
Here are some examples. This list shows all Ideas, Insights, and Features ranked by linked feedback for the last 6 months. It’s a perfect example of how unstructured information (feedback text) connects to structured and answers the question “What should we work on next?”
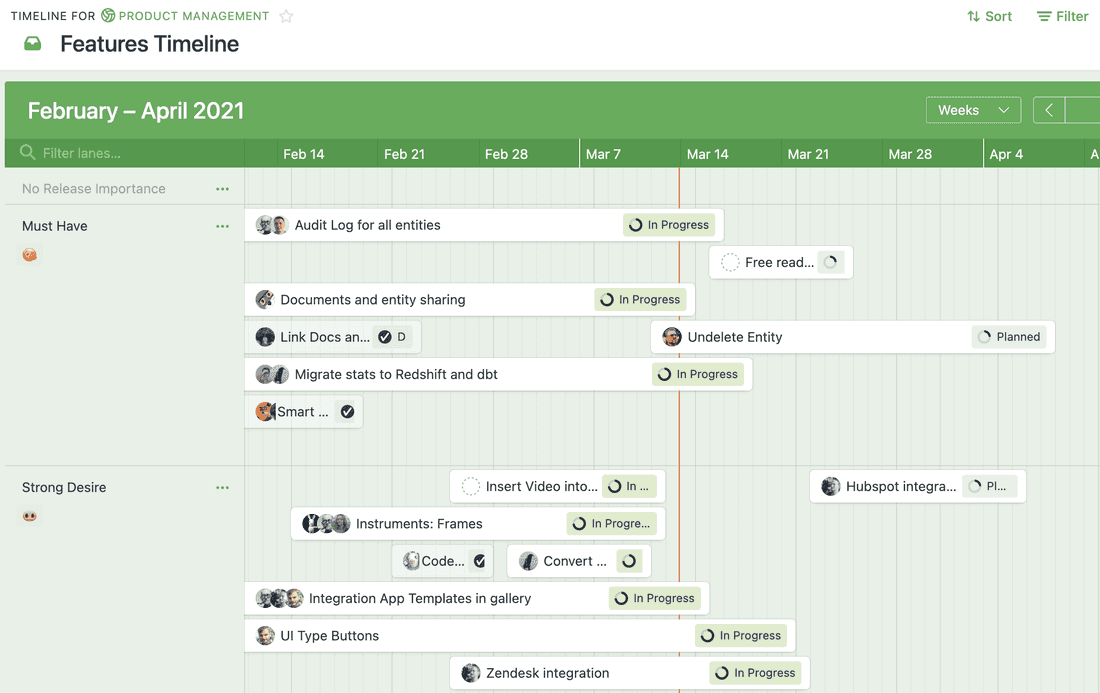
Another example is a timeline that shows all Features with forecasted completion dates. It helps to answer the question “When we will be ready for the release?”
The promise: increase the probability of insights
Now let’s get back to our original promise: increase insights probability for knowledge workers. We can’t set up a real experiment to measure how tools affect insights, but we think that a tool that accumulates, mixes, visualizes, and connects structured and unstructured information in a single space will improve knowledge discovery and increase insights probability for knowledge workers.
Creativity is just connecting things — Steve Jobs
In a nutshell, such a tool can help you ask new questions and answer open questions that have no clear answer yet.
Here is an example. Let’s apply the system to feedback management in a product company.

As a result, you have all feedback in a single place. Now you can quickly see top problems and top requests, filter them by customer segments, and focus on the most problematic product areas for your current top segment. There are no tools on the market right now that can do that.
Now let’s apply the system to strategic planning in any company.
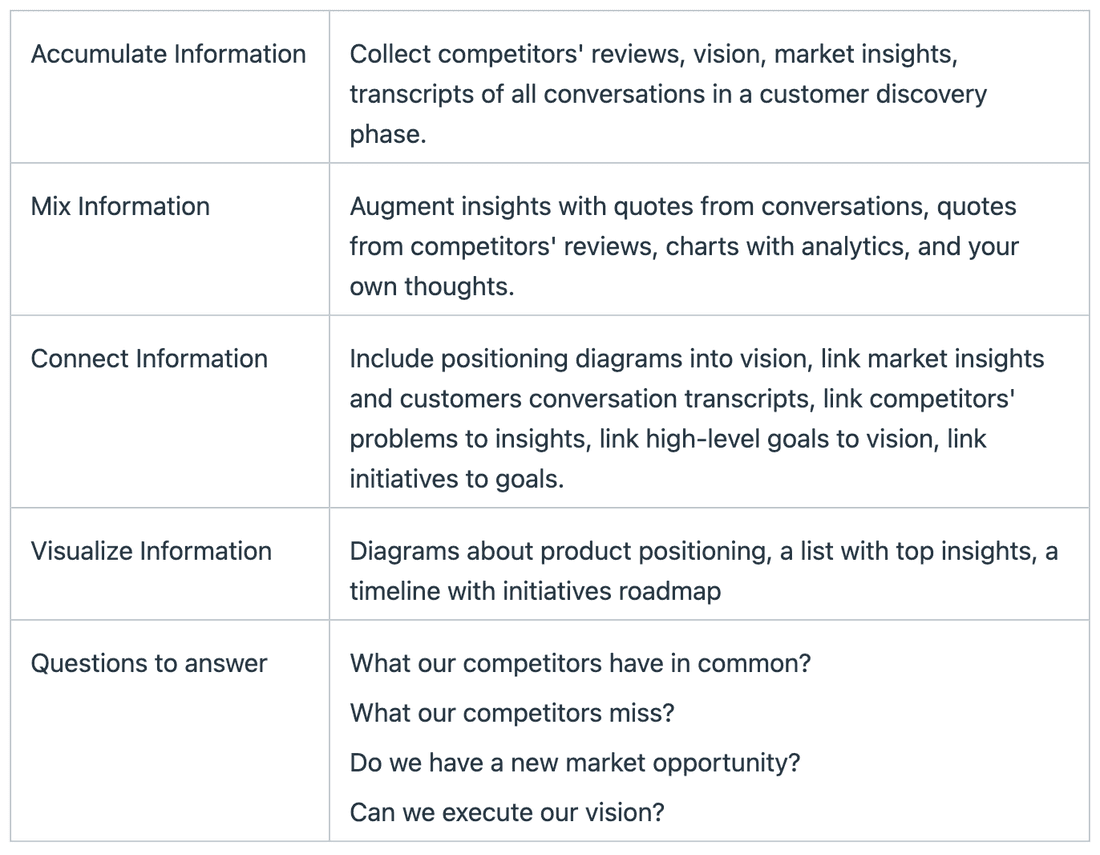
Now we have a space that connects all accumulated information about the market and potential business solutions. We can answer questions about top competitors’ problems, rank our insights, spot new niches, and plan the execution.
How to inject this tool into organizations?
People will adopt the tool when friction is low. The low friction can be achieved when the tool is very similar to existing tools on the surface but can unfold its depth when needed.
How to start? The simplest way to start is to use the tool for a single process instead of any other tool. Let’s say, a company doesn’t have a tool for OKR tracking yet. This is a perfect starting point. This tool can mimic the OKR tool and, with comparable pricing, there should be no obstacles for a company to go for it. Since it can mimic many existing tools (Trello, Jira, Asana, Airtable, Dovetail, etc), there will be many potential starting points for a company.
The next step is adding new processes. This demands deeper tool understanding and may take time. However, people tend to use existing tools for many processes. It’s almost inevitable that new processes will follow and with 2-3 connected processes value will become visible.
Big Bang attempts to replace many existing tools will fail in most cases, since they will be met with resistance and negation. Mimicry and guerilla tactics will work better.
Summary
Here is the aftermath. First, let’s summarize the most important problems that impede organization intelligence.
🚨 Organizations accumulate information in different places
All organizations use dozens or hundreds of tools to accumulate information: Notes, Spreadsheets, CRM, Project management tools, etc.
- Knowledge management and work management separation create a false dichotomy that is reflected in tools and approaches. Information lives in many tools, so you can’t really navigate it in a unified way.
- Many tools increase knowledge fragmentation in organizations. It is hard to create, connect and discover knowledge.
- With deeper tools specialization, we are losing more and more context and maybe even de-augment organizations.
In the perfect world, the knowledge tool is singular and has well connected things, like a brain.
🚨 Organizations just store knowledge and put little attention to connections
This is super-weird in fact. Connections are what help us invent new things and generate insights. Without connections, information is often undiscoverable.
There are two reasons for that behavior:
- Most note-taking/wiki software doesn’t have good enough tools to create, navigate, and manage connections.
- Explicit connection creation is a heavy cognitive task, so people tend to skip it.
In the perfect world, connections are automatic and vast, like in a brain. In a semi-perfect world, we at least have good tools to create and manage connections.
🚨 Organizations handle knowledge evolution poorly
Knowledge evolves, processes evolve, structures evolve. It all means that you can’t solidify any tool and expect it to survive. However, that is how most of the existing tools are designed. You often have a fixed domain to work with limited extendability. This may shorten the organization’s life-span since eventually, the company becomes blind and rigid.
In the perfect world, knowledge evolves in a tool, like in a brain. Our tool should support information and connections evolution, mutation, and recombination.
🌶 A single tool concept
A single tool that accumulates, mixes, connects, and visualizes structured and unstructured information in a single space will improve knowledge discovery and increase insights probability for knowledge workers.
It seems it’s technologically possible to create a viable tool as a web-based app, but it’s not clear how it will scale for large organizations above 1K people.
We know Fibery is not there yet, but we have a vision that illuminates our future development. We’re committed to pursuing the long-term goal: help small and medium organizations become more intelligent.
See you in 2030. The end. 🦐
Psst... Wanna try Fibery? 👀
Infinitely flexible product discovery & development platform.
More gems from our Radically Honest Blog:


Can AI-First Support Deliver - or Is Human Still Essential?
Everywhere online, you see the same headlines: AI is taking over the world. Every new model is supposedly smarter than the last (well, maybe not that much smarter, despite the marketing hype - but still, progress is undeniable).

How Fibery Handles Hiring
The Hiring Space in Fibery is built to manage the entire recruitment lifecycle, from job postings to final hiring decisions. Let's see how it works.

How Do We Work with Customers
At Fibery, we call our approach customer-centric — not because it sounds good on a landing page, but because it’s the only way to build a product people truly use and love.

Why Fibery Will Make You Feel Stupid
And why you will love it eventually. An emotional survival guide for those who feel lost. Part 1 out of many.